It’s no secret that Cloud Run offers one of the most straightforward ways for delivering AI-powered applications to production, letting developers focus on their application logic without having to worry about the underlying infrastructure or how to scale from zero to millions of users. But did you know that Cloud Run is also many customers’ platform of choice for providing their AI researchers with tools they need to run and productionize their experiments outside of their trusted Python notebooks?
Cloud Run provides a number of services on top of the container runtime that offer a comprehensive platform for building and running AI-powered applications. In this article, Google highlight some of key features of Cloud Run that help speed up the development of AI-powered applications:
- Time to market – by easily moving from prototyping in Vertex AI Studio to a deployed containerized application
- Observability – by using Cloud Run’s built-in SLO monitoring and Google Cloud observability solutions
- Rate of innovation – trying multiple versions of your service in parallel with revisions and traffic splitting
- Relevance and factuality – building RAG implementations by directly and securely connecting to Cloud databases.
- Multi-regional deployments and HA – by fronting multiple Cloud Run services behind a single external global application load balancer
From prototyping in AI Studio to publishing a Cloud Run service
Many gen AI-based products start in Vertex AI Studio, which allows for rapid prototyping on a range of models without the need for writing code. From there, the “Generate Code” functionality offers a handy segway for turning experiments into code in one of several popular programming languages.

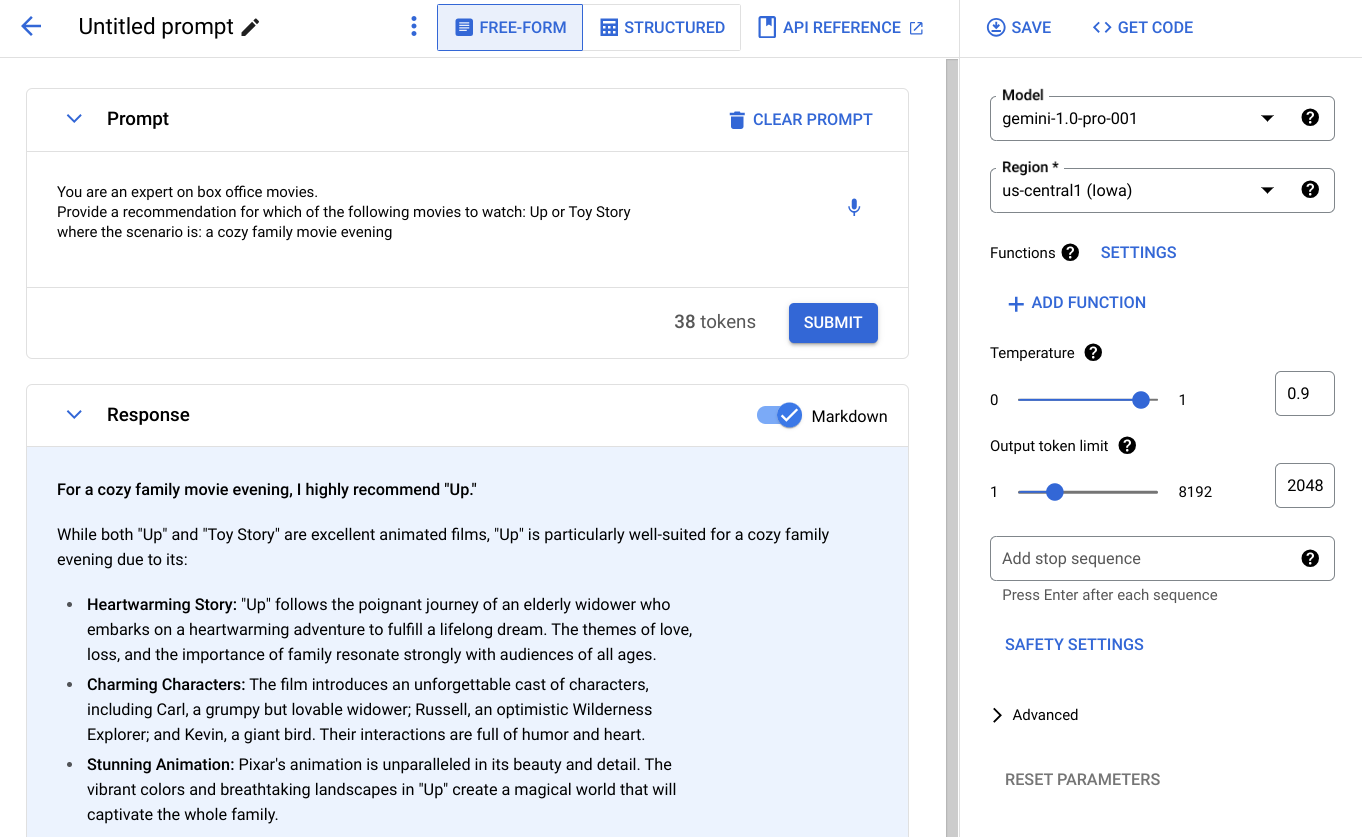
The generated code snippet consists of a script that invokes the Vertex AI APIs that offer the AI service. Depending on the type of application you are trying to build, the process of turning that script into a web application might be as easy as turning the hardcoded prompt into a templated string and wrapping it all in a web framework. For example, in Python, this could be done by wrapping the prompt in a small Flask application and parametrizing the request with a simple Python f-string:
from flask import Flask, request, jsonify
import os
import vertexai
import logging
from vertexai.preview.generative_models import GenerativeModel
import vertexai.preview.generative_models as generative_models
app = Flask(__name__)
vertexai.init(project=os.getenv("PROJECT_ID"), location=os.getenv("GCP_REGION"))
model = GenerativeModel("gemini-1.0-pro-001")
def vertex_movie_recommendation(movies, scenario):
try:
response = model.generate_content(
f"""You are an expert on box office movies.
Provide a recommendation for which of the following movies to watch: {" or ".join(movies)}
where the scenario is: {scenario}""")
return response.text
except Exception as e:
logging.exception(e)
return "Unable to generate recommendation."
@app.route('/recommendations', methods=['POST'])
def movie_recommendations():
"""
Returns movie recommendation based on the user's input.
"""
if not request.json:
return jsonify({'error': 'Missing JSON payload'}), 400
movies = request.json['movies']
scenario = request.json['scenario']
recommendation_response = vertex_movie_recommendation(movies, scenario)
return jsonify({'recommendation': recommendation_response})
if __name__ == '__main__':
port = int(os.environ.get('PORT', 8080))
app.run(debug=True, host='0.0.0.0', port=port)
Together with a simple package.txt file that includes the required dependencies, we can already containerize and deploy our application. Thanks to Cloud Run’s support for Buildpacks we don’t even need to provide a Dockerfile to describe how our container should be built.
With a simple gcloud command the application is ready to serve traffic:
gcloud run deploy movie-recommendation-eu \
--source . \
--set-env-vars GCP_REGION=europe-west1
Monitor application performance with SLOs and telemetry
Implementing observability is crucial to both ensuring that the application meets user expectations and capturing the business impact that the application provides. Cloud Run offers both Service Level Objective (SLO) monitoring and observability out of the box.
Monitoring SLOs is an important way to start managing your application on the basis of Error Budgets and then use that metric to balance stability and rate of innovation. With Cloud Run, SLO monitoring can be defined on the basis of availability, latency, and custom metrics.

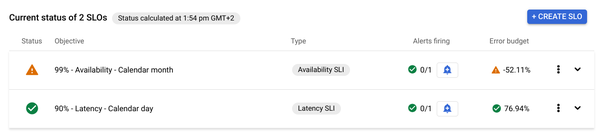
Traditional observability in the form of logging, monitoring, and tracing is also available out of the box and directly integrates with Google Cloud Observability to collect all the relevant data in a central place. Tracing in particular has proven to be invaluable for investigating the latency decomposition of AI applications. It is often used to better understand complex orchestration scenarios and RAG implementations.
Rapid innovation with concurrent revisions and Cloud Deploy
Many AI use cases fundamentally rethink how we approach and solve problems. Because of the nature of LLMs and the effects of parameters like temperature or nuances in prompting, the overall outcome are oftentimes hard to predict. Having the ability to run experiments in parallel can therefore help innovate and iterate quickly.

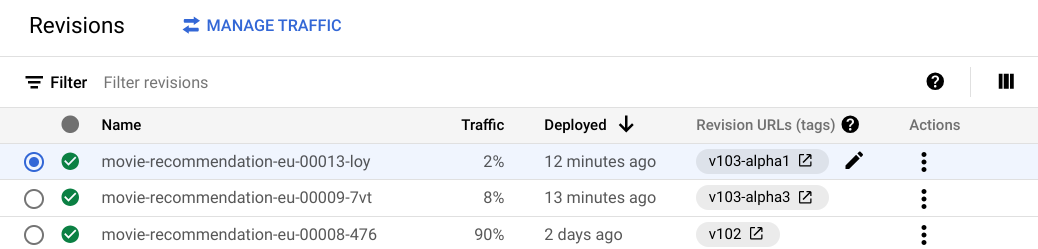
Cloud Run’s built-in traffic splitting allows developers to run multiple concurrent versions of different revisions of a service at once, and fine-grained control over how traffic should be distributed amongst them. For AI applications, this could mean that different versions of a prompt could be served to different sets of users and compared on the basis of a common success metric like click-rate or probability of purchase.
Cloud Deploy offers a managed service to orchestrate the rollout of different revisions of a Cloud Run service automatically. It also integrates with your existing development flows such that a deployment pipeline can be triggered through push events in source control.
Connecting to cloud databases to integrate with enterprise data
Sometimes a static pre-trained model can’t generate accurate responses because it lacks the specific context of a domain. In many cases, providing additional data in the prompt through techniques like retrieval-augmented generation (RAG) can help provide the model with enough contextual information to make the model’s responses more relevant for a specific use case.

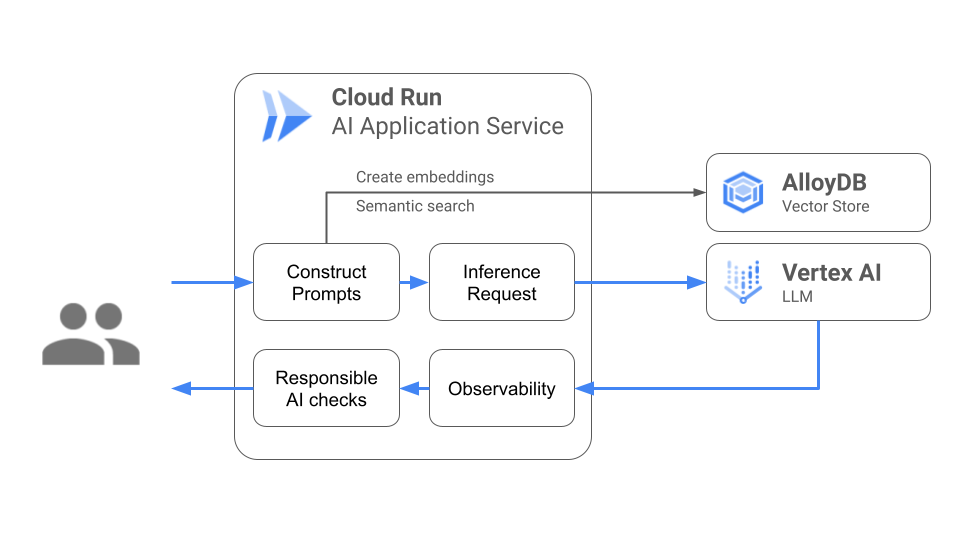
Cloud Run provides direct and private connectivity from the orchestrating AI application to cloud databases like AlloyDB or Cloud SQL that can then be leveraged as a vector store for RAG implementations. With direct VPC egress capabilities Cloud Run can now connect to private database endpoints without the extra step of a serverless VPC connector.
Custom domains and multi-regional deployments
By default any Cloud Run service receives a URL in the form of <service-name>.<project-region-hash>.a.run.app that can be used to access the service with HTTP requests. This is handy for quick prototyping and internal services but often it presents two problems.
First, that URL is not very memorable, and the domain suffix does not map to the service provider. It’s therefore impossible for consumers of the service to identify whether this is a legitimate service. Even the SSL certificate is issued to Google and does not provide information about the ownership of that service.
The second concern is that if you scale your service to multiple regions to provide HA and lower latency to your distributed user base, the different regions will have different URLs. This means that switching from one service region to another has to be done at the client or DNS level and isn’t transparent to users.

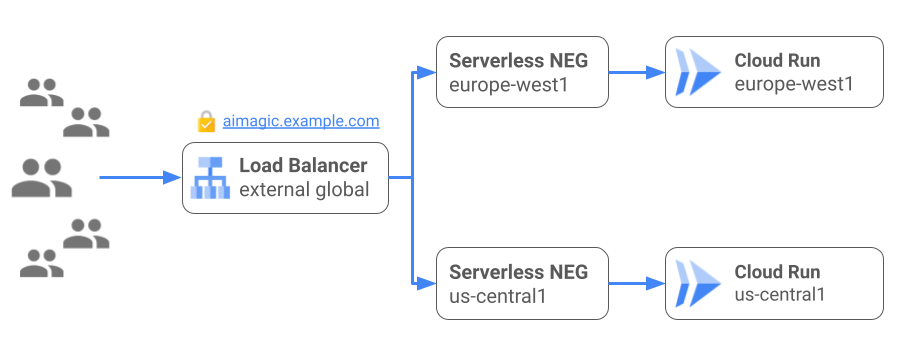
To solve for both of these problems, Cloud Run offers support for custom domain names and the ability to unify Cloud Run deployments in different regions behind a global external load balancer with a single external IP address based on anycast. With the load balancer in place you can run your AI service with a custom domain, your own certificate and the ability to failover manually in a regional outage scenario.
Let Cloud Run power your AI app
Google explored five different aspects that make Cloud Run a natural starting point for building AI-powered applications on top of the powerful services provided by Vertex AI.
If you’re interested in building RAG-capable generative AI applications with Cloud Run, then this solution blueprint is a fantastic resource to dive deeper into the different architectural building blocks. If you think generative AI applications in Cloud Run have to be written in Python then this session from Cloud Next will show you how to build AI applications in a familiar Java-based enterprise environment.