Scaling workloads often comes with a hefty price tag, especially in streaming environments, where latency is heavily scrutinized. So it makes sense Google want Google pipelines to run without bottlenecks — because costs and latency grow with inefficiencies!
This is especially true for most modern autotuning strategies: whenever there are hot keys or hot workers bottlenecking processing and building up backlogs, data freshness suffers. Apache Kafka is an example of a streaming environment that can create hot spots in the pipeline. An autoscaler may try to compensate after the fact with additional compute units. However, this is not only costly, it’s also slow. An autoscaler only reacts after there’s a backlog of accumulated messages and incurs overhead spinning up new workers.
To help, Google recently introduced load balancing in Dataflow to help with source reads. By better distributing workloads and proactively relieving overwhelmed workers with load balancing, Google are able to push more data with less resources and lower latencies.
Real user gains
The following are production pipelines from top Dataflow customers that have benefitted from the load balancing rollout.
Case 1 – Load balancing reduced user-worker scaling events and allowed the pipeline to operate with better performance with fewer workers. (75% lower workers resulted in a daily cost reduction of 64% in Google Compute Engine, and the backlog dropped from ~1min to ~10s)


dataflow.googleapis.com/job/active_worker_instances

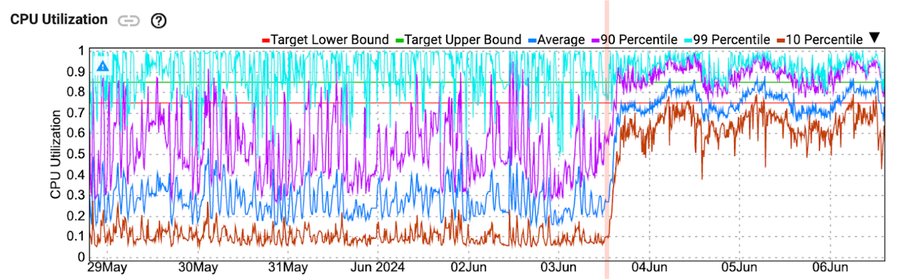
Work was offloaded to idle workers, for a jump in CPU utilization in 10th percentile
compute.googleapis.com/instance/cpu/utilization
Case 2 – Load balancing made it possible to scale with the input rate instead of stuck at maximum number of workers because of the high backlog. (57% lower worker on the same input rate resulted in a monthly cost reduction of 37% in Compute Engine, and peak backlog dropped from ~4.5 days to ~5.2 hours)


Note: Each color represents a single worker and its assigned workload, not yet available externally
Case 3 – Load Balancing allowed for +27% increased throughput with reduced backlog of ~1 day for the same number of workers.


dataflow.googleapis.com/job/estimated_bytes_produced_count
Load balancing at work
When a pipeline starts up, Dataflow doesn’t know in advance the amount of data coming in on any particular data source. In fact, it can change throughout the life of the pipeline. Therefore, when there are multiple topics involved, you may end up in the following situation:


If worker 1 is unable to keep up with the 30 MB/s load, then you will need to bring up a third worker to handle topic 2. You can achieve a better solution with load balancing: rebalance and let the pipeline keep up with just two workers.
With load balancing enabled, work is automatically and intelligently distributed by looking at the live input rate of each topic, preventing hot workers from bottlenecking the entire pipeline. This extends beyond unbalanced topics; it can also find per-key-level imbalances and redistribute keys among workers*, achieving balance at the core.

