Google are introducing the new Vertex AI Model Monitoring, a re-architecture of Vertex AI’s model monitoring features, to provide a more flexible, extensible, and consistent monitoring solution for models deployed on any serving infrastructure (even outside of Vertex AI, e.g. Google Kubernetes Engine, Cloud Run, Google Compute Engine and more).
The new Vertex AI Model Monitoring aims to centralize the management of model monitoring capabilities and help customers continuously monitor their model performance in production thanks to:
- Support for models hosted outside of Vertex AI (e.g. GKE, Cloud Run, even multi-cloud & hybrid-cloud)
- Unified monitoring job management for both online and batch prediction
- Simplified configuration and metrics visualization attached to the model, not the endpoint
In this article, you will not only get an introduction to the core concepts and capabilities of the new Vertex AI Model Monitoring, but also see how you can use the new Vertex AI Model Monitoring for monitoring your models in production.
Introduction to the new Vertex AI Model Monitoring
In a typical monitoring approach for a deployed model version, prediction request-response pairs (i.e. input feature and output prediction pairs) are captured and collected. These inference logs are consumed in monitoring jobs, either on-demand or scheduled, to assess how well the model performs. The configuration of the monitoring job may include the inference schema, monitoring metrics, objective thresholds, alert channels, and schedule frequency. If anomalies are detected, alerts can be sent through different channels (e.g. email, Slack, and more) to notify the model owners, who can then investigate the anomaly and start a new training cycle.
The new Vertex AI Model Monitoring represents the model version with the Model Monitor resource and the associated monitoring job with the Model Monitoring job resource.

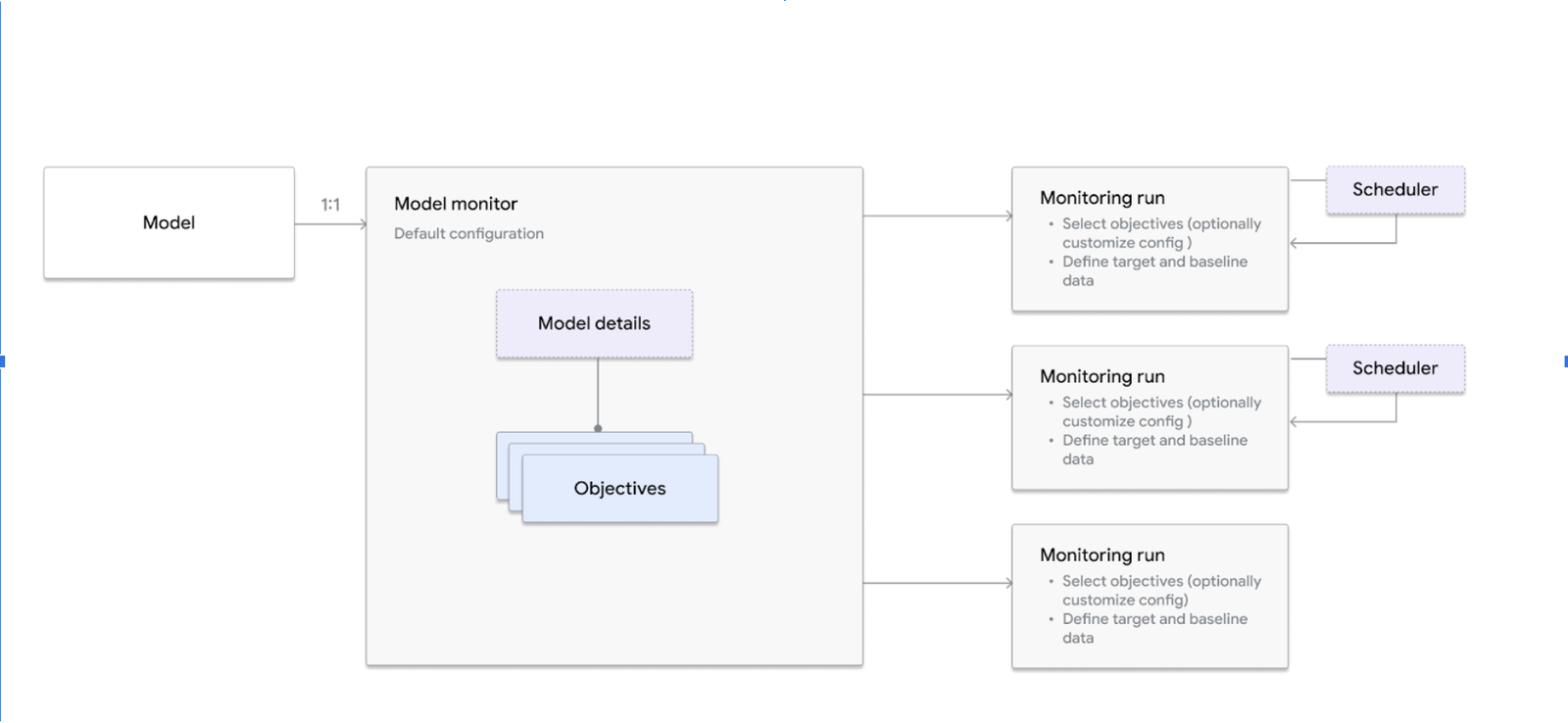
The Model Monitor is a monitoring representation of a specific model version in Vertex AI Model Registry. A Model Monitor can store the default monitoring configuration for the training dataset (called baseline dataset) and production dataset (called reference dataset) and a set of monitoring objectives you define for monitoring the model.
A Model Monitoring job represents a single batch execution of the Model Monitoring configuration. Each job processes data, calculates a data distribution with associated descriptive metrics, the drift of a data distribution of predictions and features from the training distribution, and potentially triggers alerts according to the thresholds you define. And a Model Monitoring job can be on-demand or scheduled for continuous monitoring over a sliding time window with one or more customizable monitoring objectives.
Now that you know some of the key concepts and capabilities of the new Vertex AI Model Monitoring, let’s see how you can leverage them to improve the process of monitoring your models in production. In particular, this article focuses on showing you how to use the new Vertex AI Model Monitoring to monitor a referenced model registered but not imported to Vertex AI Model Registry.
Monitoring an external model with Vertex AI Model Monitoring
Let’s assume that you build a customer lifetime value (CLV) model for predicting how valuable a customer is to your company. The model is in production in your own environment (e.g. GKE, GCE, Cloud Run) and you want to use the new Vertex AI Model Monitoring to monitor the quality of the model.
To use the new Vertex AI Model Monitoring for monitoring a model which is not hosted on Vertex AI (AKA referenced model), you start by preparing the baseline and the target datasets. In this scenario, those datasets represent the training features values in a particular point in time (baseline dataset) and their corresponding production values (target dataset).
Then you store the dataset either to Cloud Storage or BigQuery. Cloud Storage and BigQuery are just two of the supported data sources for Vertex AI Model Monitoring. For more information, please refer to the documentation. Below you have an example of the target dataset you might have with a CLV model.
Next, you register a Reference Model in Vertex AI Model Registry and you define the associated Model Monitor. With the Model Monitor, you set the model to monitor and the associated model monitoring schema which includes feature name and the associated data types. And with a Reference Model, the resulting model monitoring artifacts will be recorded in the Vertex AI ML Metadata for governance and reproducibility. Here you have an example of how to create a Model Monitor using Vertex AI SDK for Python.lang-py
from vertexai.resources.preview import ml_monitoring
from vertexai.resources.preview.ml_monitoring.spec import ModelMonitoringSchema
feature_fields = get_feature_fields(prod_df)
model_monitoring_schema = ModelMonitoringSchema(feature_fields=feature_fields)
clv_model_monitor = ml_monitoring.ModelMonitor.create(
display_name="clv_model_monitor",
model_name=model_placeholder.resource_name,
model_version_id="1",
model_monitoring_schema=model_monitoring_schema)
Where ModelMonitoringSchema represents the schema of the features you want to monitor.
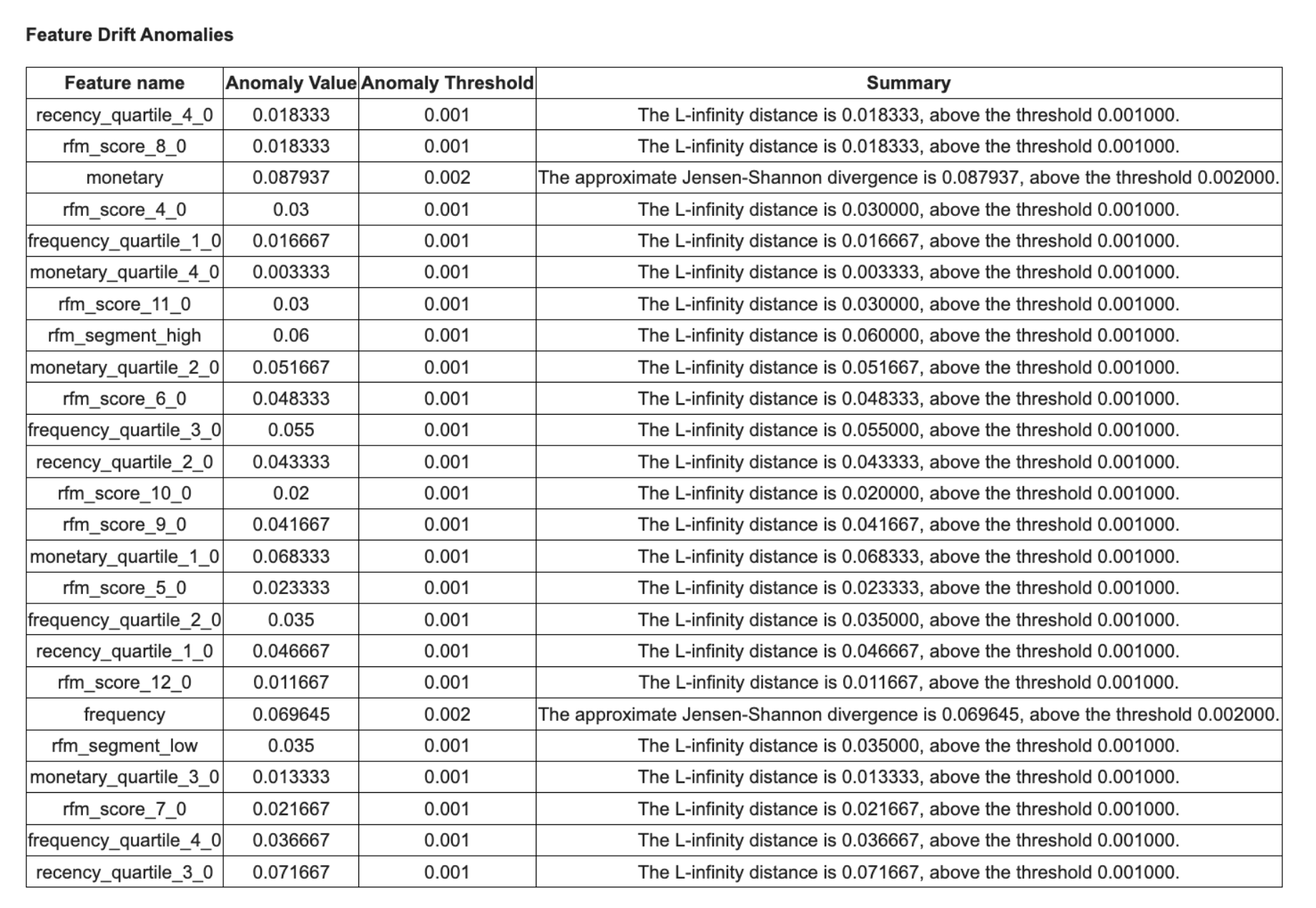
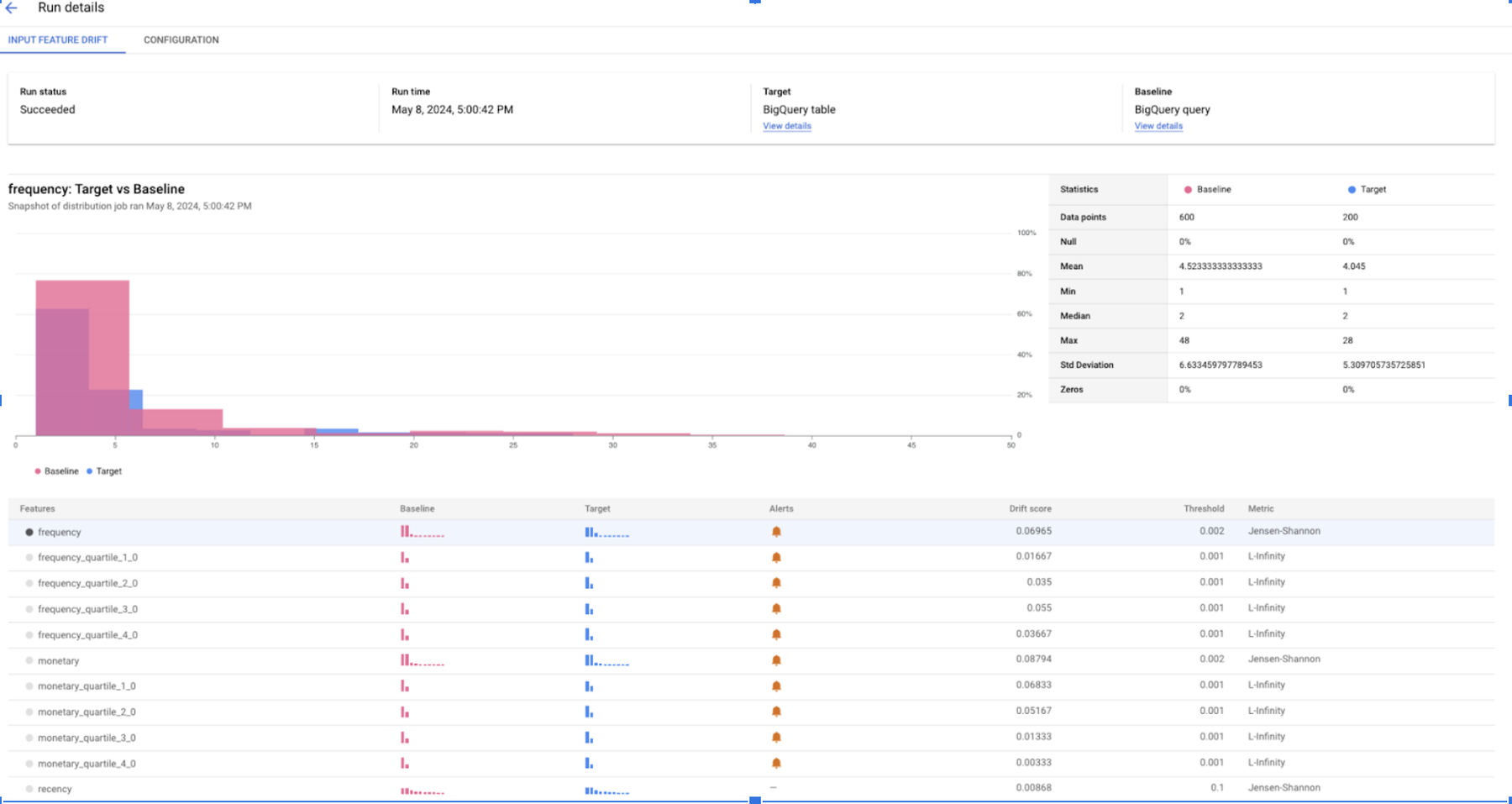
After you have created the Model Monitor and you have prepared your baseline and target datasets, you are ready to define and run the Model Monitoring job. When you define the Model Monitoring job, you need to decide what to monitor and how to monitor the model if something unexpected happens. About what to monitor, the new Vertex AI Model Monitoring lets you define several monitoring objectives. You can leverage the new Vertex AI Model Monitoring for tracking input feature, output prediction, and feature attribution data drift for categorical, numerical and all types of data against a user-defined threshold. Depending on the data type of your features, you can use L-infinity distance and Jensen-Shannon divergence metrics to measure the difference between training (baseline) and production (target) features distributions. Consequently, when the differences in distance for any feature surpass the associated threshold, an alert will be triggered.
About how to monitor the model, the new Vertex AI Model Monitoring gives you the flexibility to run a monitoring job one-time or schedule regular jobs for continuous monitoring. Also the new Vertex AI Model Monitoring supports several notification channels including Gmail and Slack you can use for reviewing monitoring results. You can see how to define and run a one-time Model Monitoring job using Vertex AI SDK for Python in the following example.lang-py
from vertexai.resources.preview.ml_monitoring.spec import DataDriftSpec, NotificationSpec, MonitoringInput, TabularObjective, OutputSpec
# Define feature monitoring thresholds
feature_thresholds = {
'recency' : 0.1,
'rfm_score_3_0' : 0.2,
'rfm_segment_medium': 0.3
}
# Define feature drift configuration
feature_drift_config = DataDriftSpec(
categorical_metric_type="l_infinity",
numeric_metric_type="jensen_shannon_divergence",
default_categorical_alert_threshold=0.001,
default_numeric_alert_threshold=0.002,
feature_alert_thresholds=feature_thresholds)
baseline_dataset=MonitoringInput(
timestamp_field="feature_timestamp",
query="SELECT * FROM `your-baseline-bq-table-uri`")
target_dataset=MonitoringInput(
table_uri='bq://your-predictions-bq-table-uri')
model_monitoring_job = clv_model_monitor.run(
display_name='your-model-monitoring-job',
baseline_dataset=baseline_dataset,
target_dataset=target_dataset,
tabular_objective_spec=TabularObjective(
feature_drift_spec=feature_drift_config),
notification_spec=NotificationSpec(user_emails=['your-email'],),
output_spec=OutputSpec(gcs_base_dir='your-monitoring-results-bucket-uri')
)
In our case, right after you run the one-time monitoring job, you would receive an email alert like the following message to inform you that a model monitoring job has started.

And after a while, if some anomalies are detected, you would receive an email as this one with a detailed report about detected anomalies.

And you can also verify those anomalies by using the new Vertex AI Model Motoring UI which provides even more information about features distributions and how they diverge between training and production.

How Telepass monitor ML models using the new Vertex AI Model Monitoring
In the rapidly evolving world of toll and mobility services, Telepass has emerged as a leading provider across Italy and numerous European countries. In recent years, Telepass made a strategic decision to accelerate the development of machine learning solutions by embracing MLOps. Within the past year, Telepass has successfully implemented a comprehensive MLOps platform, enabling the robust deployment of various ML use cases.
As of today, the Telepass team has utilized this MLOps framework to develop, test, and seamlessly deploy – through continuous deployment – more than 80 training pipelines that run monthly. These pipelines cover over 10 distinct use cases, including precise churn prediction for forecasting customer attrition, propensity modeling for tailored customer interactions, and data-driven customer clustering strategies.
Despite these achievements, Telepass realized that they lacked a system for identifying feature drift and an event-driven re-training mechanism triggered by anomalies in data distribution. To address this need and integrate monitoring into their existing MLOps framework to automate the re-training process, Telepass partnered with Google Cloud as an early adopter of Vertex AI Model Monitoring.
In the words of Telepass:
“Through strategic integration of the new Vertex AI Model Monitoring alongside our established Vertex AI infrastructure, our team has achieved unparalleled heights in model quality assurance and MLOps efficiency. By facilitating timely retraining, we consistently elevate our performance, delivering impactful outcomes that exceed the expectations of our stakeholders.”
What’s next
Are you struggling in monitoring your AI/ML model at scale?
With the new Vertex AI Model Monitoring, you can manage model monitoring of any of your models and ensure their performance in production.