Generative AI agents introduce immense potential to transform enterprise workspaces. Enterprises from almost every industry are exploring the possibilities of generative AI, adopting AI agents for purposes ranging from internal productivity to customer-facing support. However, while these AI agents can efficiently interact with data already in your databases to provide summaries, answer complex questions, and generate insightful content, concerns persist around safeguarding sensitive user data when integrating this technology.
The data privacy dilemma
Before discussing data privacy, Google should define an important concept: RAG (Retrieval-Augmented Generation) is a machine-learning technique to optimize the accuracy and reliability of generative AI models. With RAG, an application retrieves information from a source (such as a database), augments it into the prompt of the LLM, and uses it to generate more grounded and accurate responses.
Many developers have adopted RAG to enable their applications to use the often-proprietary data in their databases. For example, an application may use a RAG agent to access databases containing customer information, proprietary research, or confidential legal documents to correctly answer natural language questions with company context.
A RAG use- case: Cymbal Air
Like any data access paradigm, without a careful approach there is risk. A hypothetical airline we’ll call Cymbal Air is developing an AI assistant that uses RAG to handle these tasks:
- Book flight ticket for the user (write to the database)
- List user’s booked tickets (read from user-privacy database)
- Get flight information for the user, including schedule, location, and seat information (read from a proprietary database)
This assistant needs access to a wide range of operational and user data, and even potentially to write information to the database. However, giving the AI unrestricted access to the database could lead to accidental leaks of sensitive information about a different user. How do we ensure data safety while letting the AI assistant retrieve information from the database?
A user-centric security design pattern
One way of tackling this problem is by putting limits on what the agent can access. Rather than give the foundation model unbounded access, we can define specific tool functions that the agent uses to access database information securely and predictably. The key steps are:
- Create a tool function that runs a pre-written SQL query
- Attach a user authentication header to the tool function
- When a user asks for database information, the agent parses parameters from user input, and feed the parameters to the tool function
In essence, we designed the authentication system based on the usage of user-authenticated tool functions that is opaque to the foundation model agent.

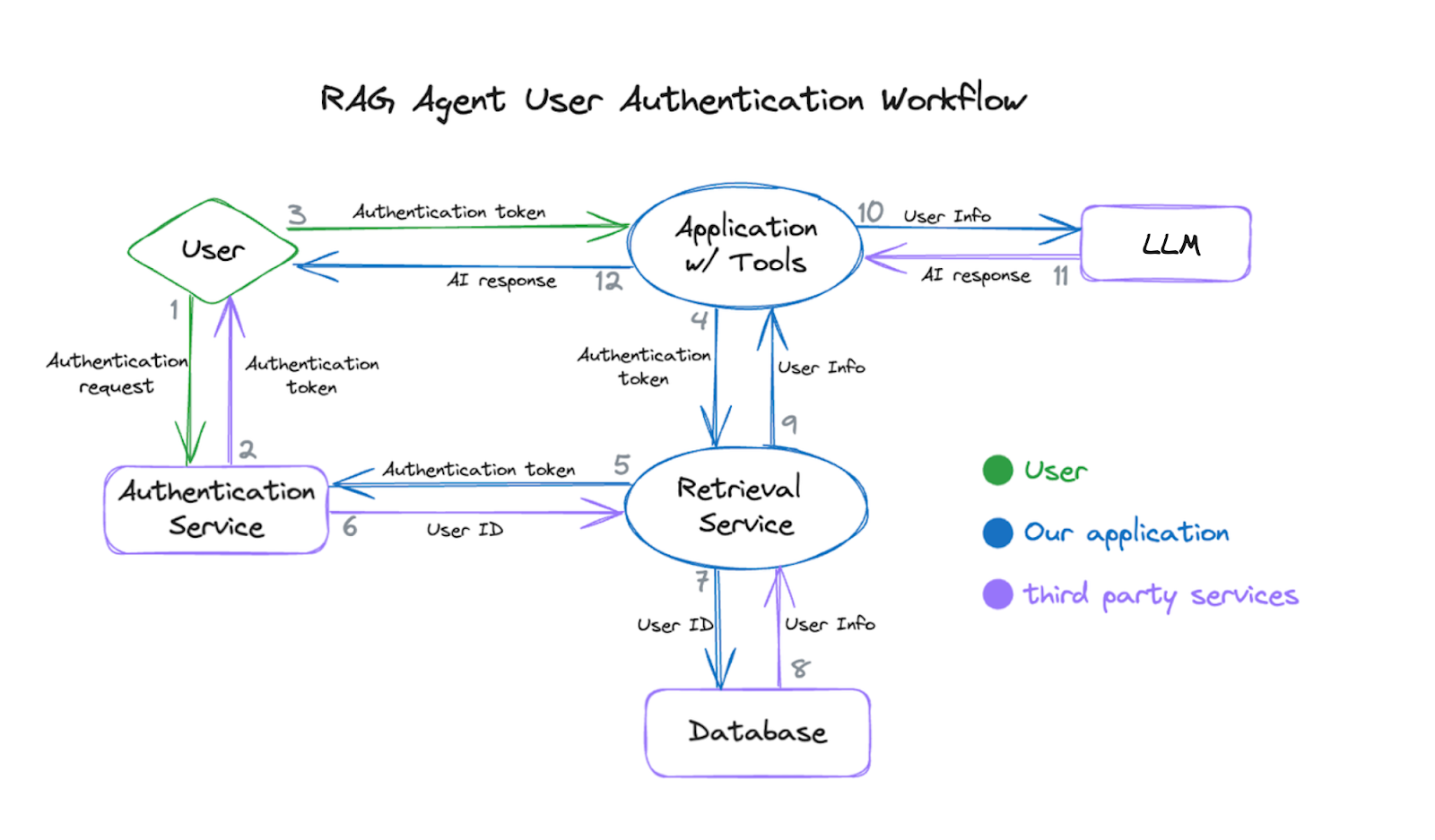
Authentication and workflow
Let us take a look at the authentication workflow:
- Obtain a user authentication token
- The application requests user login and receives an authentication token from the authentication service.
- The application attaches the user’s authentication token to the tool function’s request headers.
- Send a request to the retrieval service
- The user asks the agent for information from the database.
- The agent uses the tool functions to send requests to the retrieval service.
- Verify the authentication token and query the database
- The retrieval service parses the user authentication token from the request header.
- The retrieval service verifies the user authentication token and receives the user ID from the authentication service.
- The retrieval service uses the user ID (not visible to the user or the foundation model agent) to query the database to get the user information.
- Send information back to the agent
- The application gets a response from the retrieval service containing the user information.
- The application feeds the user information to the foundation model.
- The agent responds to the application, which forwards response to the user.
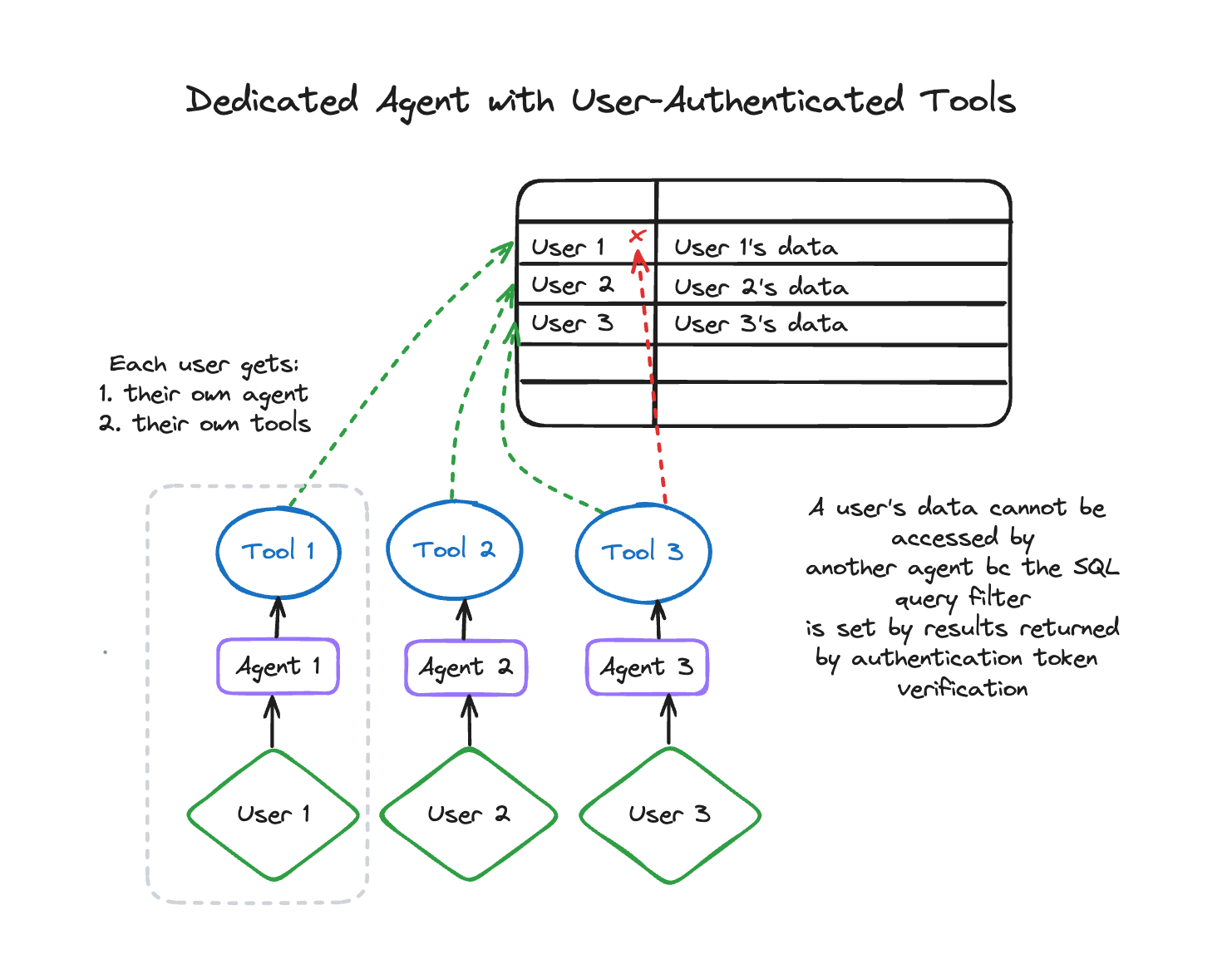
Why is this authentication design safer?
Throughout the entire process, the AI agent can never see every user’s data at once–instead, it only has access to the rows relevant to the authenticated user. In this way, each user gets a dedicated AI assistant, which only has access to that logged-in user’s information.
Building the app
Let’s explain how we can build an app with such a user authentication feature. There are two main components:
- Application layer: The orchestrated layer containing the foundation model-based agent implementation and the predefined tools, which attach a user authentication token with each request to the retrieval service.
- Retrieval Service: This service acts like the security guard for your database, ensuring each user only has authorized access. It double-checks a user’s token and uses that information to exclusively pull data from the database the user is allowed to see.
Implement user authentication feature

Application layer
Below is a code example of one approach to construct Tool requests in LangChain. The Tools should be created in the application layer.
- Create a ‘get_id_token()’ function that sends a request to the authentication server to retrieve the user’s authentication token.
- Attach the user authentication token to the request header.
- Generate a LangChain Tool from the user-authenticated `list_ticket()` function.
def get_id_token():
... # Step 1
return id_token
def get_headers(client: aiohttp.ClientSession):
"""Helper method to generate ID tokens for authenticated requests"""
headers = client.headers
headers["User-Id-Token"] = f"Bearer {get_id_token()}"
return headers
def generate_list_tickets(client: aiohttp.ClientSession):
async def list_tickets():
response = await client.get(
url=f"{BASE_URL}/tickets/list",
headers=get_headers(client), # Step 2
)
response = await response.json()
return response
return list_tickets
# Step 3
list_ticket_tool = StructuredTool.from_function(
coroutine=generate_list_tickets(client),
name="List Tickets",
description="""
Use this tool to list a user's flight tickets.
Takes no input and returns a list of current user's flight tickets.
""",
)
Retrieval service
The receipt endpoint in the retrieval service processes requests from the application layer in the following steps:
- Parse the user authentication token from the request header
- Verify the token with the authentication service to get the user ID
- Send predefined a SQL query to retrieve the user’s information from the database
- Return the results to the application
async def get_user_info(request):
headers = request.headers
# Step 1
token = _ParseUserIdToken(headers)
# Step 2
id_info = id_token.verify_oauth2_token(token, requests.Request())
return {"user_id": id_info["sub"],}
@routes.get("/tickets/list")
async def list_tickets(request: Request):
user_info = await get_user_info(request)
if user_info is None:
raise HTTPException(status_code=401,
detail="User login required for database access.",)
# Step 3
async with self.__pool.connect() as conn:
s = text("SELECT * FROM tickets WHERE user_id = :user_id")
params = {"user_id": user_id,}
results = (await conn.execute(s, params)).mappings().fetchall()
res = [models.Ticket.model_validate(r) for r in results]
# Step 4
return results
Bringing it to life: The Cymbal Air demo
During the whole workflow, this traveler’s ticket information is protected by this user authentication design, where the AI assistant’s memory and authentication token are both associated with the user login, therefore each user gets their own agent with their own set of authenticated tools.