A SQL Server DBA has many options for transferring data from one SQL Server instance to a new environment – those options can be overwhelming. This blog aims to help you decide what option you might want to choose for your specific migration scenario. We’ll walk through several steps for deciding on a migration plan:
- Evaluating your application and database migration requirements
- Migration approaches – continuous vs one-time
- Deep-dive on different migration paths
Evaluating your application and database needs for migration
We first need to define the different application-specific factors that will help us with choosing a migration approach. Several common questions customers consider:
- How long will migration take?
- Will my apps continue to work during the migration?
- How complex is the support of such migration and how easy is the rollback process?
To answer these questions, you need to evaluate your application and database to have better understanding of the migration process as we are making the decision:
- What is your Downtime Tolerance?
Some applications have well defined Change Request schedules, which can be used for the migration, while others are developed to run 24/7 with high uptime. Knowing the acceptable downtime will allow you to weigh the complexity of the continuous migration options with the simplicity of one-time approaches. - How big is your database?
Migrating large databases may pose additional challenges, like a prolonged increased resource utilization on on-premises servers to support the migration or how to deliver database snapshots in Transactional Replication. Transfer rates that can look simple on a surface become less simple accounting for different challenges one can face uploading multi-terabyte backups to the cloud. - What is the daily size of updates to your database?
Size of the daily updates and the net change of those updates can both have a major impact on the decision between one-time and continuous migration approaches. For example when net db size is smaller than log of all changes in case your workload updates a significant part of the database with multiple changes to the same set of rows or follows a wipe and load data refresh strategy, you can look to schedule a series of one-time migrations instead of continuous migration. On the other hand, if changes are limited and appear during an extended time, you may want to look at an online migration approach.
Migration approaches
Migration approaches fall into two buckets: one-time migrations or continuous migrations. In one-time migrations, you are taking a copy of your source database, transferring it to your destination instance, and then switching over your application to point to the new instance. In continuous migrations, data is copied from your source instance to your destination instance on an ongoing basis – starting with an initial data load – and the application(s) may gradually switch over days, weeks, or months later.
Depending on your downtime tolerance, or if you have an infrequently updated database, you may choose to go with one-time migration. This approach employs several options with different levels of process complexity from the least complex – import database backup to average complexity of Snapshot Replication.
If there are a significant number of daily changes in your database and a requirement of a minimal downtime, continuous migration options are likely better for your application. Continuous migration scenarios are usually based on data replication technologies supported by SQL Server which includes Transactional, Merge Replications, p2p and Bidirectional replications and based on SQL Server Agent, Snapshot, Log Reader and Distribution Agents. Other replication technologies may leverage Change Data Capture (CDC), Change Tracking or even custom triggers to capture and store incremental data changes combining this with their own delivery mechanisms.
Cloud SQL for SQL Server supports Push Transactional Replication, which we will explore in more detail in Part 2, along with CDC-based migration tools offered by Google Cloud partners, which you can find in the Google Cloud Marketplace.
One-time migration

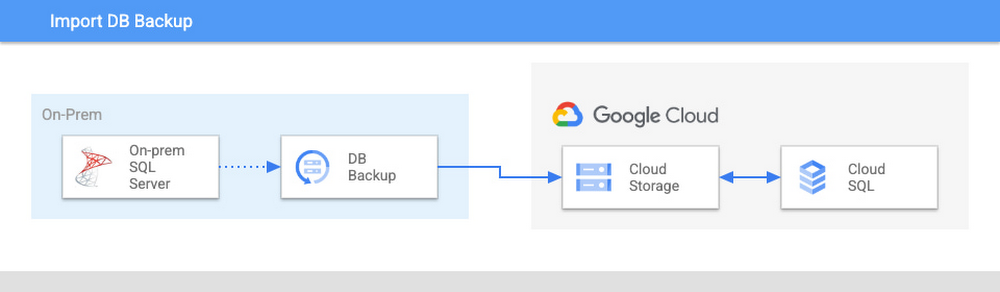
One of the simplest ways to migrate your database to Cloud SQL is to import it from a backup. This approach is suitable for any database size and if you are focused on a one-time migration, import from a backup becomes an increasingly appealing choice as instance size grows, mostly driven by differences in performance this option has compared to options described below when working with huge amounts of data. Striped backups should be used for 5TB+ DBs due to file size limitations.

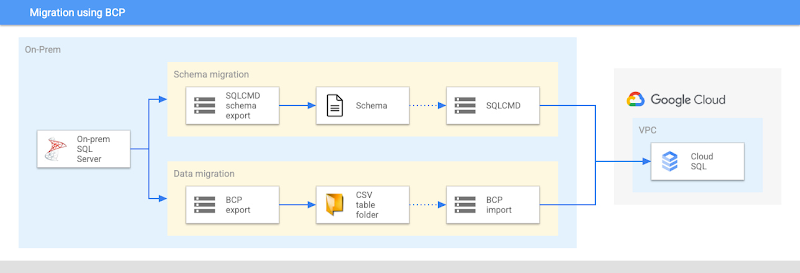
Another option, while slower, may benefit teams that already have table extracts and using BCP tools to load their on-prem databases – the same will work with your Cloud-hosted instances.
BCP can be used in standalone process as well, you would need to:
- Generate and apply database schema – for example using SQL Server Management Studio (SSMS) generate scripts wizard.
- Extract table data using BCP tool to a folder on a machine that is accessible to BCP tool (for example, the machine BCP tool is installed on) and can connect to your Cloud SQL instance. If filtering is required, you can use the “QUERYOUT” option to supply your own query criterias.
- Import table data from a folder to Cloud SQL.

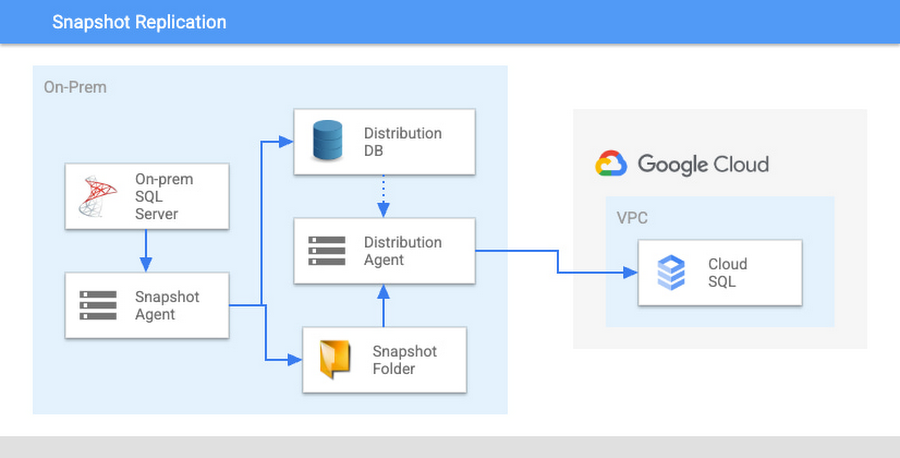
If you want to move specific objects, or don’t want to transfer files manually, you can use Snapshot Replication.
While this is a step up in complexity compared to backup import, this article describes in detail the steps you would take. Snapshot replication will introduce additional resource load on your on-prem server like extra space for storing the snapshot, as well as IO and CPU resources for transferring and generating it. Some types of workloads may not be supported and may block or reset the snapshot generation process. Depending on the database schema and article configuration used there is also a limitation on objects supported by this type of replication and some potential that additional steps would be required to cut over to the replica, so we would recommend consulting with SQL Server documentation for example starting with this article. All of the additional work and caveats of Snapshot Replication have several additional advantages over the simple Import/Export approach – granularity of the objects being replicated/migrated, one click re-initialization to apply updated snapshot to target server, and established reporting and monitoring tooling.
Snapshot generation will keep a lock on the source tables until the process is complete. This may pose an issue for larger databases as the run time can extend to hours. Consider importing from a backup or Push Transactional Replication with Snapshot Agent initialization if this lock would affect your workloads. In contrast to Snapshot Replication, Transactional replication keeps locks for a fraction of the time and incorporates updates into the transaction log to be sent with incremental changes).
Continuous Migration
When your workloads can’t be stopped for the downtime required to take a backup and import it into Cloud SQL you can use one of the following continuous migration approaches: using one of Push Transactional Replication setups or CDC based custom replication.
Push Transactional Replication
Transactional Replication comes in many shapes and forms, allowing for very flexible replication setups. As of the time of writing this article, among all types of replication Cloud SQL supports Push Transactional replication as publisher and as a subscriber, which allows setup of continuous replication to a Cloud SQL instance from an external source, create additional replicas in Cloud SQL, or replication from Cloud SQL to an external destination (for example, for a multi-environment DR scenario)
Continuous migration using Push Transactional Replication can be viewed as a set of 3 steps:
- Initial Seed: Before sending incremental updates to Cloud SQL, you need to copy over the initial data snapshot. There are a number of ways to do this – backup, Snapshot Agent job, BCP etc., each with its own benefits and features.
- Incremental updates: Incremental updates are being sent to the replica instance. Depending on the replication settings, replica can be not only available, the database can be queried (read-only in most cases).
- Cut over to Cloud SQL: Due to certain limitations required for transactional replication to work, final changes to the database schema are required to fully cut over workloads to Cloud SQL instances. This may include changes like adding/enabling triggers, updating identity field ranges, synchronizing logins, converting views back from tables, etc.
Replication with initialization from a backup:
This is a one stop shop to set up your schema and initial seed data transfer for all server supported objects. Additionally, this works for any database size, and provides optimal performance for larger instances where other methods of initialization like Snapshot Agent, BCP, etc., have disadvantages. While this option requires a custom prepared backup file (your usual backups will not work until publications are created and marked to allow initialization from a backup), you still can use non-prepared backups with manual initialization discussed below.
Replication with a Snapshot Agent:
An initial seed with a Snapshot Agent works well with compatible, moderately-sized databases, on instances with enough spare resources to finish the phase. As with Snapshot Replication, this approach allows for granularity in migration and added flexibility in restarting the process at any time with just a few clicks. Another advantage is an integrated transactional replication monitoring feature that shows the status and progress of both the Snapshot Agent and the Distribution Agent replication jobs.
Replication with manual initialization:
This option has the same benefits and limitations as “initialization from a backup”, with a small but significant difference – developers can choose a synchronization point for the start of the Transactional Replication. This allows the initial seeding with any previously discussed option or custom tooling available; the Transactional Replication takes care of the rest.
A key consideration when choosing among the transactional replication initial seed methods is your database size – 1Tb+ databases are more reliably initiated from backups, while smaller ones could benefit from ease of reinitialization with a Snapshot Agent. If your database has static tables without primary keys, or otherwise unsupported objects, we recommend using backup or manual initialization options.
Incremental updates:

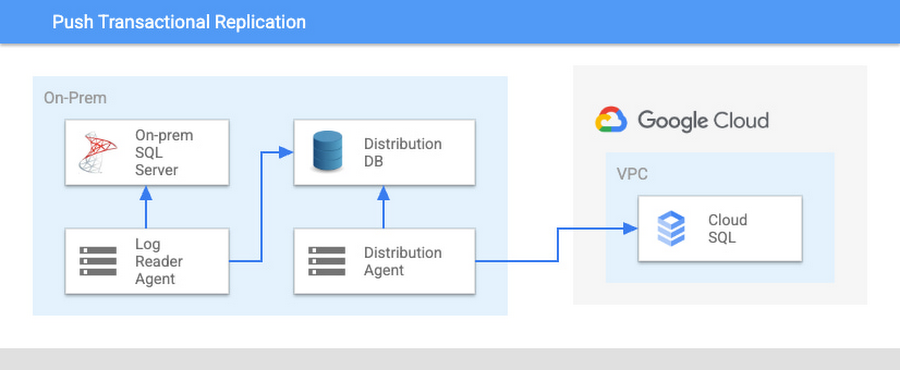
The Log Reader Agent running at the Distributor location (which can be the same as source or a separate SQL Server instance for migrating to Cloud SQL and on a Cloud SQL instance as source) gathers the incremental updates for all published database objects from the source instance by reading data modification statements and storing them in a distribution database. The agent can run as a periodical sweep of transactions or as a continuous setup, decreasing potential replication lag between the source and target instances.
The Distribution Agent reads the distribution database and applies undistributed commands at the target instance. As incremental changes are no longer benefiting from the BCP performance that we might have seen with an initial seed replication, the high data turnover rates in combination with a large database size may need an additional transactional replication setup tuning for efficiency. It is important to validate your migration setup on test instances before attempting an actual migration, to avoid unintended delays and timeouts.
Migration complexity
Google has explored many different migration technologies, and each has potential sources of complexity that can vary depending on the specific database being migrated. Four major steps can be sources of complexity:
- File transfer to Cloud SQL: Smaller databases should have few issues with backup upload or download, while larger databases in TB+ territory may have additional needs, such as the use of striped backups, compression techniques, or filtering.
- Setting up a database with an initial seed: Approaches that include a restore of a database backup step includes restoration of the database schema, while BCP or a custom tooling approaches may need the schema to be in place. During a manual setup of the database schema, you might need to update the identity ranges, set trigger execution orders, etc., increasing the complexity and increasing the need for DBA and/or developer involvement.
- Fine-tuning replication settings: Snapshot Replication and Transactional Replication approaches may need test runs to validate the schema and workload compatibility with replication and to find the correct replication settings. DBA involvement is highly recommended at all steps of the process. Setup of monitoring, reporting, and alert systems is recommended in case replication is set to run for an extended time. We can estimate replication approaches as moderate complexity to high complexity.
- Finalizing the database setup for application cut-over: Snapshot Replication, Transactional Replication, BCP, and some 3rd party tooling do not finish their part of the migration with a complete database replica migrated, possibly having it in a half-ready state. Inconsistencies may include incorrect identity ranges, turned off (or missing) triggers, missing users, and so on. What is migrated and in what capacity depends on the database schema and compatibility level with the migration approach chosen. We highly recommend doing migration test runs with schema comparison to identify possible deficiencies, preparing “pull up” scripts for database promotion, and application cutover to the Cloud SQL instance.
Not all of the complexities affect all of the discussed approaches. As examples, file transfers are irrelevant for Snapshot Replication, and the fine-tuning of replication settings is irrelevant to importing a database backup.
Copying data out of Cloud SQL for SQL Server
Some customers want to copy data from Cloud SQL to another destination, often as part of a multi-cloud strategy. In a nutshell, every approach we discussed above has an opportunity to be run in reverse:
- One-time migration
- Database backup export
- BCP or similar tools usually works both ways for import and export
- Snapshot Replication using predefined stored procedures, this guide can help you with the process for both Snapshot Replication and Transactional Replication setups
- Continuous migration
- Push Transactional Replication with a Snapshot Agent and with manual initialization can use predefined stored procedures
- Push Transactional Replication with a Backup can be achieved by the predefined stored procedures to create publications and create a backup. During restore, please note the LSN and use the “initialize from LSN” option to add a subscriber. Another option is to use a “replication support only” subscription.
Let’s review our options
One-time migrations are the most convenient and simple approach to migrate a snapshot of your database to Cloud SQL, contrasting with continuous migration approaches that allow you to keep your target and source instances in sync with each other while your workloads continue to run.
A universal recommendation is to go with a database backup import in all cases where possible. If that is not working, a one-time migration of smaller databases, with simple schemas and requirements in periodic refreshes Snapshot Replication might help. If table file extracts are already part of your workflows, or you already use ETL jobs and have spare development time or a need, respective BCP import and custom tooling are possibilities with benefits.
Push transactional replication allows you to keep your source and target servers in sync. The main difference in approaches is the initialization, otherwise called the initial seed. There are no universal recommendations though. You will have to work through the options and choose the best-fitting one. Is it Snapshot Agent or backup initialization, manual initialization or custom ETL jobs? Testing is required from the beginning to the full cut-over to ensure no surprises during the initial seed, replication process, or final promotion.