With generative AI top of mind for both developers and business stakeholders, it’s important to explore how products like Workflows, Google Cloud’s serverless execution engine, can automate and orchestrate large language model (LLM) use cases. We recently covered how to orchestrate Vertex AI’s PaLM and Gemini APIs with Workflows. In this article, Google illustrate how Workflows can perform long-document summarization, a concrete use case with wide applicability.
Open-source LLM orchestration frameworks like LangChain for Python and TypeScript developers, or LangChain4j for Java developers, integrate various components such as LLMs, document loaders, and vector databases, to implement complex tasks such as document summarization. You can also use Workflows for this task without investing significant time in an LLM orchestration framework.
Summarization techniques
It’s easy enough to summarize a short document by entering the document’s entire content as a prompt into an LLM’s context window. However, prompts for large language models are usually token-count-limited. For longer documents, a different approach is required. Two common approaches are:
- Map/reduce — A long document is split into smaller sections that fit the context window. For each section, a summary is created, and a summary of all the summaries is created as a final step.
- Iterative refinement — Similar to the map/reduce approach, we evaluate the document in a piecemeal fashion. A summary is created for the first section, then the LLM refines its first summary with the details from the following section, and iteratively through to the end of the document.
Both methods yield good results. However, the map/reduce approach has one advantage over the refinement method. With refinement, you have a sequential process, as the next section of the document is summarized using the previously refined summary.
With map/reduce, as illustrated in the diagram below, you can create a summary for each section in parallel (the “map” operation), with a final summarization in the last step (the “reduce” operation). This is faster than the sequential approach.

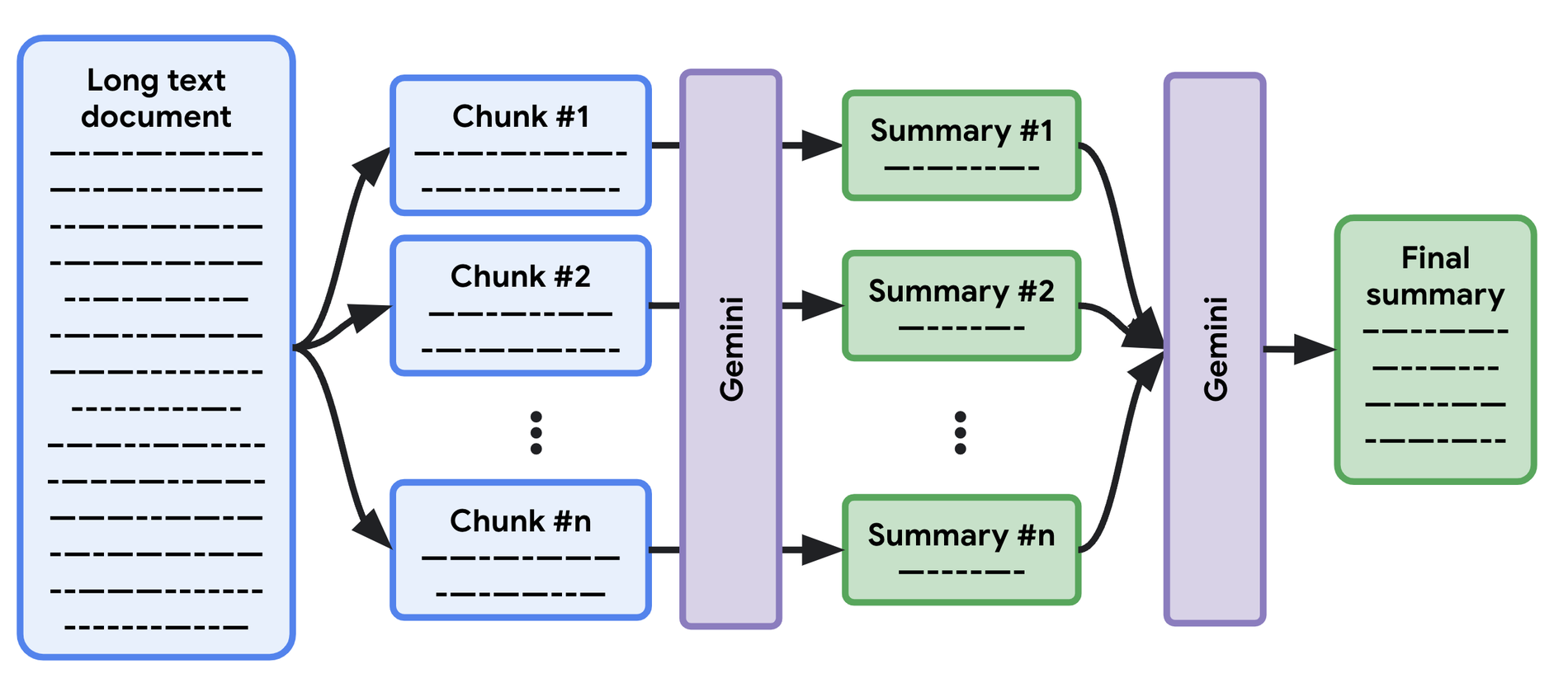
Long document summarization with Workflows and Gemini models
In a previous article, Google showed how to call PaLM and Gemini models via Workflows, and highlighted a key feature of Workflows: parallel step execution. With this feature, Google can create summaries of the long document sections in parallel.
Here’s a bird’s-eye view of the workflow definition:
- The workflow is triggered when a new text document is added to a Cloud Storage bucket.
- The text file is split into “chunks” that are summarized in parallel steps.
- A final summarization step groups all the smaller summaries and combines them into a single summary.
- All the calls to the Gemini 1.0 Pro model are made thanks to a subworkflow.
Let’s see that in action.
Retrieving the text file and summarizing sections in parallel (“map” part)
main:
params: [input]
steps:
- assign_file_vars:
assign:
- file_size: ${int(input.data.size)}
- chunk_size: 64000
- n_chunks: ${int(file_size / chunk_size)}
- summaries: []
- all_summaries_concatenated: ""
- loop_over_chunks:
parallel:
shared: [summaries]
for:
value: chunk_idx
range: ${[0, n_chunks]}
steps:
- assign_bounds:
assign:
- lower_bound: ${chunk_idx * chunk_size}
- upper_bound: ${(chunk_idx + 1) * chunk_size}
- summaries: ${list.concat(summaries, "")}
- dump_file_content:
call: http.get
args:
url: ${"https://storage.googleapis.com/storage/v1/b/" + input.data.bucket + "/o/" + input.data.name + "?alt=media"}
auth:
type: OAuth2
headers:
Range: ${"bytes=" + lower_bound + "-" + upper_bound}
result: file_content
- assign_chunk:
assign:
- chunk: ${file_content.body}
- generate_chunk_summary:
call: ask_gemini_for_summary
args:
textToSummarize: ${chunk}
result: summary
- assign_summary:
assign:
- summaries[chunk_idx]: ${summary}
The assign_file_vars step prepares a few constants and data structures. Here, we chose 64,000 characters as our chunk size, so they can fit in the LLM’s context window and stay within Workflow’s memory limits. We also have variables for the lists of summaries, and one to hold the final summary.
The loop_over_chunks step extracts each chunk of text in parallel, first by loading each portion of the document from Cloud Storage in the dump_file_content sub-step. It then calls the Gemini model-powered subworkflow in generate_chunk_summary that summarizes that section of the document. We finally store the current summary in the summaries array.
A summary of summaries (“reduce” part)
Now that we have all the chunk summaries, we can summarize all the smaller summaries into an aggregate summary, or final summary of summaries if you will:
- concat_summaries:
for:
value: summary
in: ${summaries}
steps:
- append_summaries:
assign:
- all_summaries_concatenated: ${all_summaries_concatenated + "\n" + summary}
- reduce_summary:
call: ask_gemini_for_summary
args:
textToSummarize: ${all_summaries_concatenated}
result: final_summary
- return_result:
return:
- summaries: ${summaries}
- final_summary: ${final_summary}
In concat_summaries we concatenate all the chunk summaries. In the reduce_summary step, we call our Gemini model summarization subworkflow one last time to get the final summary. And in return_result, we return the results, including the chunk summaries, and the final summary.
Asking the Gemini model for summaries
Both our “map” and “reduce” steps call a subworkflow that encapsulates the call with Gemini models. Let’s zoom in on this final part of our workflow:
ask_gemini_for_summary:
params: [textToSummarize]
steps:
- init:
assign:
- project: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- location: "us-central1"
- model: "gemini-1.0-pro"
- summary: ""
- call_gemini:
call: http.post
args:
url: ${"https://" + location + "-aiplatform.googleapis.com" + "/v1/projects/" + project + "/locations/" + location + "/publishers/google/models/" + model + ":generateContent"}
auth:
type: OAuth2
body:
contents:
role: user
parts:
- text: '${"Make a summary of the following text:\n\n" + textToSummarize}'
generation_config:
temperature: 0.2
maxOutputTokens: 2000
topK: 10
topP: 0.9
result: gemini_response
# Sometimes, there's no text, for example, due to safety settings
- check_text_exists:
switch:
- condition: ${not("parts" in gemini_response.body.candidates[0].content)}
next: return_summary
- extract_text:
assign:
- summary: ${gemini_response.body.candidates[0].content.parts[0].text}
- return_summary:
return: ${summary}
In init, we prepare a few variables for the configuration of the LLM we want to use (in this case, Gemini Pro).
In the call_gemini step, we make an HTTP POST call to the model’s REST API. Notice how we can declaratively authenticate to this API simply by specifying the OAuth2 authentication scheme. In the body, we pass the prompt that requests a summary, as well as some model parameters like temperature, or a maximum length of the summary to be generated.
Finally, the last step of the subworkflow returns the summary to the calling steps.
The resulting summary
Saving the text of ‘Pride and Prejudice’ by Jane Austen into a Cloud Storage bucket triggers and executes the workflow, resulting in the following partial and final summaries:


Going further
For the purpose of this article, we kept the workflow simple, but it could be further improved in various ways. For example, we hard-coded the number of characters for each section to summarize, but that could be a parameter of the workflow, which could even be computed depending on the length of the model’s context-window limit.
Workflows itself also has a memory limit for the variables and data it keeps in memory, so we could handle those cases where an extra-long list of document section summaries wouldn’t fit in memory. And let’s not forget our newer large language model Gemini 1.5, which is able to receive up to one million tokens in input, and can summarize a long document in a single pass.
Of course, you can also choose to use an LLM orchestration framework, but as this example demonstrates, Workflows itself is capable of handling interesting LLM orchestration use cases.
Summary
In this article, Google explored a new use case for orchestrating LLMs with Workflows and implemented a long document summarization exercise without using a dedicated LLM framework. Google took advantage of Workflows’ parallel step capabilities to create section summaries in parallel and reduced the latency needed to create the whole summary.
Be sure to check out this sample summarization workflow in Google Workflows sample repository, and feel free to read more about accessing Vertex AI models in the Workflows documentation.