At Google Cloud Next event this past August, Google announced the preview of Duet AI in Google Cloud, which embeds the power of generative AI to provide assistance to Google Cloud users of all types to help them get more done, faster. Since the announcement, Google received a huge amount of interest from users all around the world. While Google are on-boarding more users to Duet AI in Google Cloud preview, Google would like to share some behind-the-scenes information around the journey of how we built Duet AI, especially about how Google customized the foundation models powering Duet AI to make it better serve our Google Cloud users.
Foundation Models powering Duet AI in Google Cloud
Duet AI in Google Cloud leverages multiple AI foundation models to support a variety of use cases ranging from application development; operations; data analysis and visualization; database management and migration; as well as cybersecurity.
Among many foundation models powering Duet AI in Google Cloud is a family of coding-related foundation models from Google called Codey. Codey was built on Google’s next-generation language model, and was trained on a massive dataset of high-quality source code and documentation, which allows it to understand the nuances of programming languages and generate code more accurately and efficiently. Codey supports 20+ coding languages, including Go, Google Standard SQL, Java, Javascript, Python, and Typescript. It enables a wide variety of coding tasks, helping developers to work faster and close skill gaps through code completion, generation, and chat.
Optimizing Codey for application development with Google Cloud
In order to better support Google Cloud developers and more efficiently and effectively assist them with coding related tasks when they develop applications with Google Cloud technologies and tooling, we further optimized Codey to build Duet AI in Google Cloud. And this was all done without sacrificing performance and quality on other software development tasks. Let’s take a detailed look at how Google did it.
Normally, customizing a foundation model — like Codey — to address the use cases of a specific domain, would involve multiple stages. Although the details of each stage may vary depending on an organization’s resources and application needs, the lifecycle of an foundation model application can be broadly outlined as follows:
- Data ingestion and preparation: Collecting and sanitizing domain training data
- Domain pre-training: Incorporating domain knowledge by fine-tuning the foundation model
- Instruction tuning: Tailoring the response style and format to the domain via instruction tuning
- Offline evaluation: Selecting the best model based on auto and human evaluations
- Integration: Integrating the model with other building blocks of the LLM application like serving configuration, monitoring, and guard rails

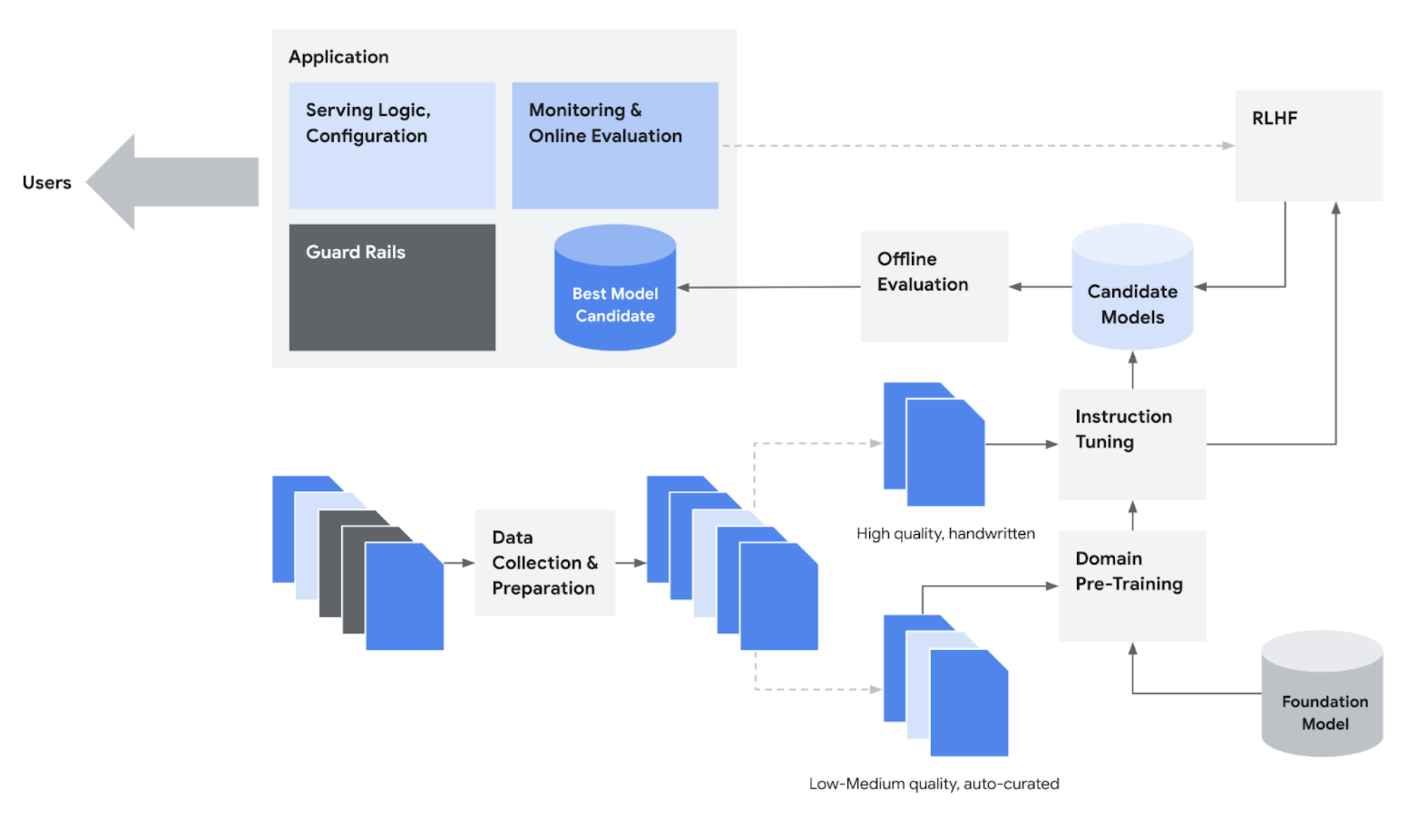
The lifecycle of a foundation model application
Let’s go over each step in more depth around how we went through the lifecycle of optimizing the foundation model to power Duet AI for Google Cloud’s specific use cases.
- Data ingestion and preparation – Google collect and prepare training data from Google Cloud data sources relevant to Google Cloud development, such as Google Cloud documentation and sample code. As part of this process, Google make sure that the training data is uniform and of high quality.
- Domain pre-training – Once the data quality is verified, we fine-tune Codey models using Google Cloud-specific training data. This step ensures that domain knowledge is well-integrated into the model while retaining some of the model’s generic natural language and coding capabilities. The exact composition of this domain pre-training mixture is usually determined empirically by training model candidates with various mixture compositions and then evaluating them against each other.
- Instruction tuning – This training step is used to improve the model’s performance in domain-specific tasks. The model responses are also aligned as closely as possible to the desired responses in terms of style, format, and safety. This requires small datasets of the highest quality. These datasets are curated, written, and rewritten by Google Cloud expert technical writers for each domain-specific task, for example: Google Cloud code generation for Client Libraries, troubleshooting QA, and SQL query generation.
- Offline evaluation – The model candidates are evaluated after each stage of training. Google use a combination of automated benchmarks (e.g., code generation, question answering) and human evaluation. For human evaluation, Google Cloud expert raters assess the model responses on a carefully selected evaluation set covering different types and subdomains of questions that we anticipate users will ask. Raters utilize criteria such as correctness, verbosity, style, and safety to holistically evaluate response quality. The consolidated evaluations are used to select the best model and/or make any adjustments to the training corpus to address any gaps or regressions.
- Integration – Once the best-performing model has been selected, we need to integrate the model with other building blocks of the foundation model application. This includes components such as serving configuration (e.g., decoding parameters, quantization), post processing (e.g., preserving context/history in multi-turn chat), telemetry (for monitoring and online evaluation), and responsible AI guardrails (e.g., toxicity checking). With all of the pieces in place, the application is ready for users.
Through the entire foundation-model application lifecycle, from the initial data ingestion to the final stage of integration, Google optimized the model with Google Cloud-specific content and expert insights to make sure Duet AI can better serve Google Cloud developers. In addition, Google integrated Duet AI across various Google Cloud surfaces such as in the Google Cloud console and directly in the UIs of a wide range of products like Cloud Code and BigQuery, to give users a more seamless user experience.