Build limitless workloads on BigQuery: New features beyond SQL
Our mission at Google Cloud is to help our customers fuel data driven transformations. As a step towards this, BigQuery is removing its limit as a SQL-only interface and providing new developer extensions for workloads that require programming beyond SQL. These flexible programming extensions are all offered without the limitations of running virtual servers.
In the keynote of our recent Next 22 conference, Google announced a way for customers to incorporate scalable and distributed machine learning and ELT jobs directly into BigQuery’s fully serverless environment with a Preview of Stored Procedures for Apache Spark. We also announced seamless movement from SQL query results to Python analysis with an integration of Google’s serverless notebook service, Colab, into BigQuery’s console. Finally, customers who want to extend BigQuery’s SQL library with custom functions written in either Cloud Functions or Cloud Run can now do so in Generally available Remote Functions.

“We’re excited for BigQuery’s commitment to a polyglot future: one in which SQL and Python data modeling can happen within the same workflow, allowing practitioners to choose the right tool for any given task. We’ve recently introduced Python support in dbt for the very same reason, and are pleased to see these new capabilities seamlessly support dbt’s data transformation workflow in BigQuery.” — Jeremy Cohen; Product Manager, dbt Labs
BigQuery Stored Procedures for Apache Spark now entering Preview
In the past, customers have found it hard to manage their data across both data warehouses and data lakes. Earlier this year, we announced BigLake, a storage engine that enables customers to store data in open file formats (such as Parquet) on Google Cloud Storage, and run GCP and open source engines on it in a secure, governed and performant manner. Today, BigQuery opens the next chapter in that story by unifying data warehouse and data lake processing by embedding the Apache Spark engine directly into BigQuery.
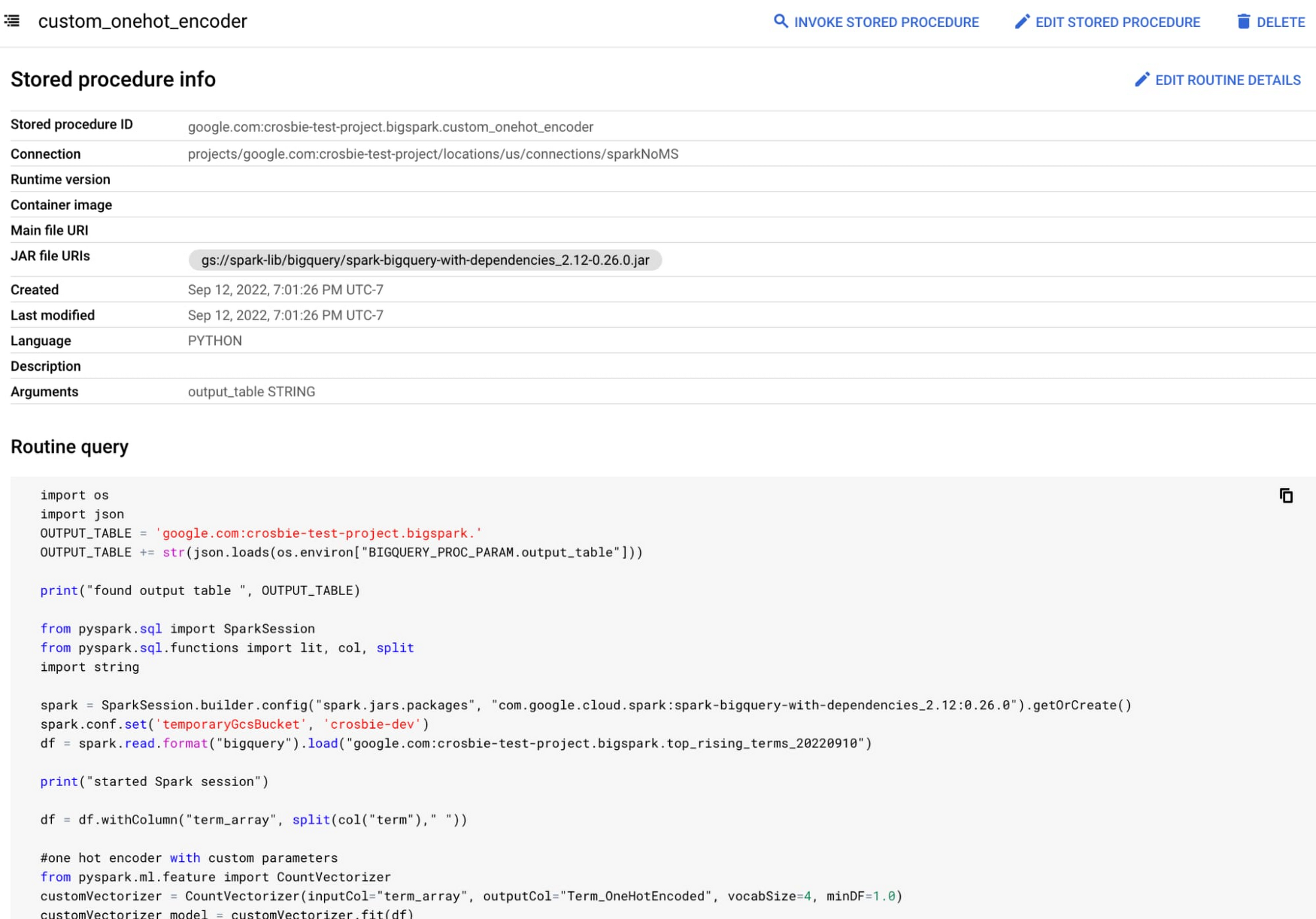
With BigQuery stored procedures for Apache Spark, you can run Apache Spark programs from BigQuery, unifying your advanced transformation and ingestion pipelines as BigQuery processes. With a stored procedure, you can schedule Apache Spark as a step in a set of SQL statements, mixing and matching the unstructured data lake objects with structured SQL queries. You can also hand off the procedures to others so they can execute Apache Spark jobs directly from SQL, so they can retrain models or ingest complicated data structures without having to understand the underlying Apache Spark code.
The cost of running these Apache Spark jobs is only based on job duration and resources consumed. The costs are converted to either BigQuery bytes processed or BigQuery slots, giving you a single billing unit for both your data lake and data warehouse jobs.
Google Colab Integration with BigQuery Console now entering Preview
For years, BigQuery customers have found Colab to be a delightful notebook-based programming experience for extending their BigQuery SQL with Python-based analysis. Customers have asked us to make it easier to move between BigQuery SQL and a Colab notebook to improve their data workflows, so that is just what we have done. Now, in Preview, a customer can jump immediately from the result of a SQL query into a notebook to do further analysis in Python, as shown in the image below. This lets you move quickly into running descriptive statistics, generating visualizations, creating a predictive analysis, or even sharing your results with others.
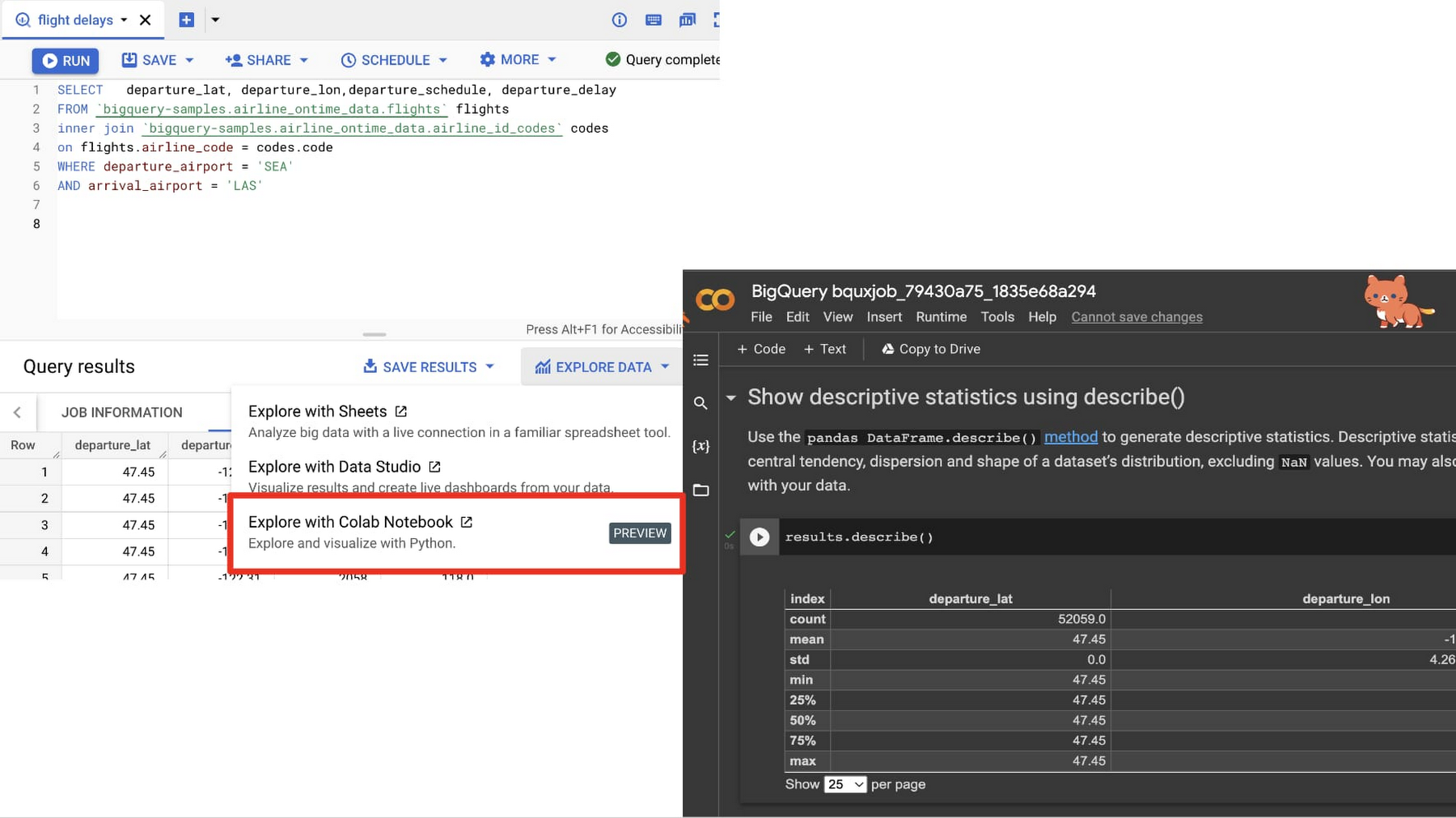
Colaboratory, or “Colab” for short, is a product from Google Research. Colab allows customers to write and execute arbitrary python code and is especially well suited to machine learning, data analysis and education. More technically, Colab is a hosted Jupyter notebook service that requires no setup to use while providing access free of charge to a limited amount of computing resources including GPUs.
This integration is available in the console today.
Remote Functions now GA
We had requests from healthcare providers who wanted to bring their existing security platforms to BigQuery, financial institutions that wanted to enrich their BigQuery data with real time stock updates, and data scientists who wanted to be able to use Vertex AI alongside BQML. To help these customers extend BigQuery into these other components, we are now making BigQuery Remote Functions Generally Available.
Protegrity and CyberRes have already developed integrations with these remote functions as a mechanism to merge BigQuery into their security platform, which will help our mutual customers address stringent compliance controls.

Remote Functions are user-defined functions (UDF) that let you extend BigQuery SQL with custom code, written and managed in either Cloud Functions or Cloud Run. A remote UDF accepts columns from BigQuery as input, performs actions on that input using custom written code, and returns the result of those actions as a value in the query result. With Remote Functions backed by Cloud Run, the SQL functions you can create are truly limitless. You have complete control and the flexibility to write BigQuery SQL functions that can be used by anyone who can write SQL. In addition, you can invoke any language with any library and binary, all with serverless pay-as-you-go infrastructure supported by Google Cloud.
You can get started by using functions in this GitHub repository of BigQuery Utils, a public listing of useful BigQuery utilities which has been extended with samples for remote functions