Article
Build gen AI agents using Google Cloud databases

As enterprises build generative AI agents to strengthen their security posture or improve their customer experience, they need access to real-time data. Because most business critical and real-time data is stored and processed in databases, you need ways to perform agentic orchestration in dynamic ways.
In this post, Google Cloud will define a new tech stack composed of models, tools, data stores, and applications. Google Cloud will show why each component is important to serving the needs of enterprise customers based on scale, performance, security, and manageability. Let's dive in.
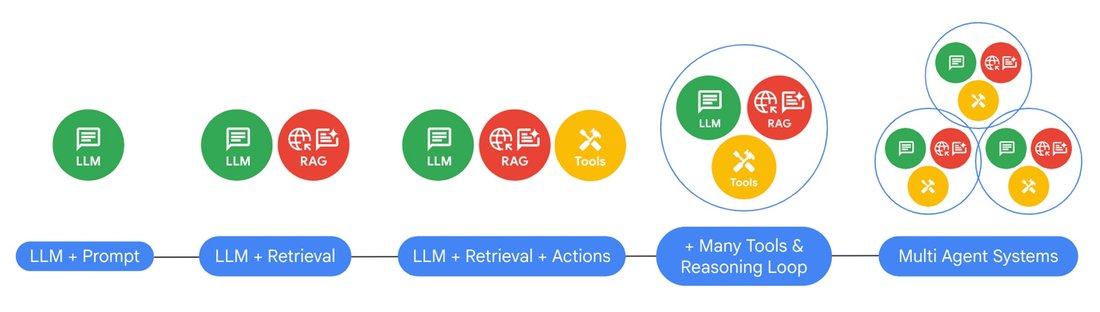
From LLMs to RAG Agents
Components of an agentic application
In the world of services, human agents have been supporting customers for decades. They’ve helped with travel reservations, insurance recommendations, and contract negotiations. “AI” agents are similar in the way they support users, but they have additional advantages. Google Cloud is seeing organizations build increasingly sophisticated AI agents to:
- Deliver hyper-personalized experiences by understanding their needs based on history
- Help employees be more productive and work better together with automated tools
- Assist the creative process by generating content and running campaigns based on objectives
- Perform complex data analysis with multiple data sources to act on signals and patterns
- Accelerate software development with AI-enabled code generation and assistance
- Strengthen security posture by mitigating attacks and increasing the speed of investigation
Agentic apps have a few additional features when compared to previous gen AI apps—they have a more sophisticated orchestration module with additional instructions which enables them to reason and plan by utilizing various tools.
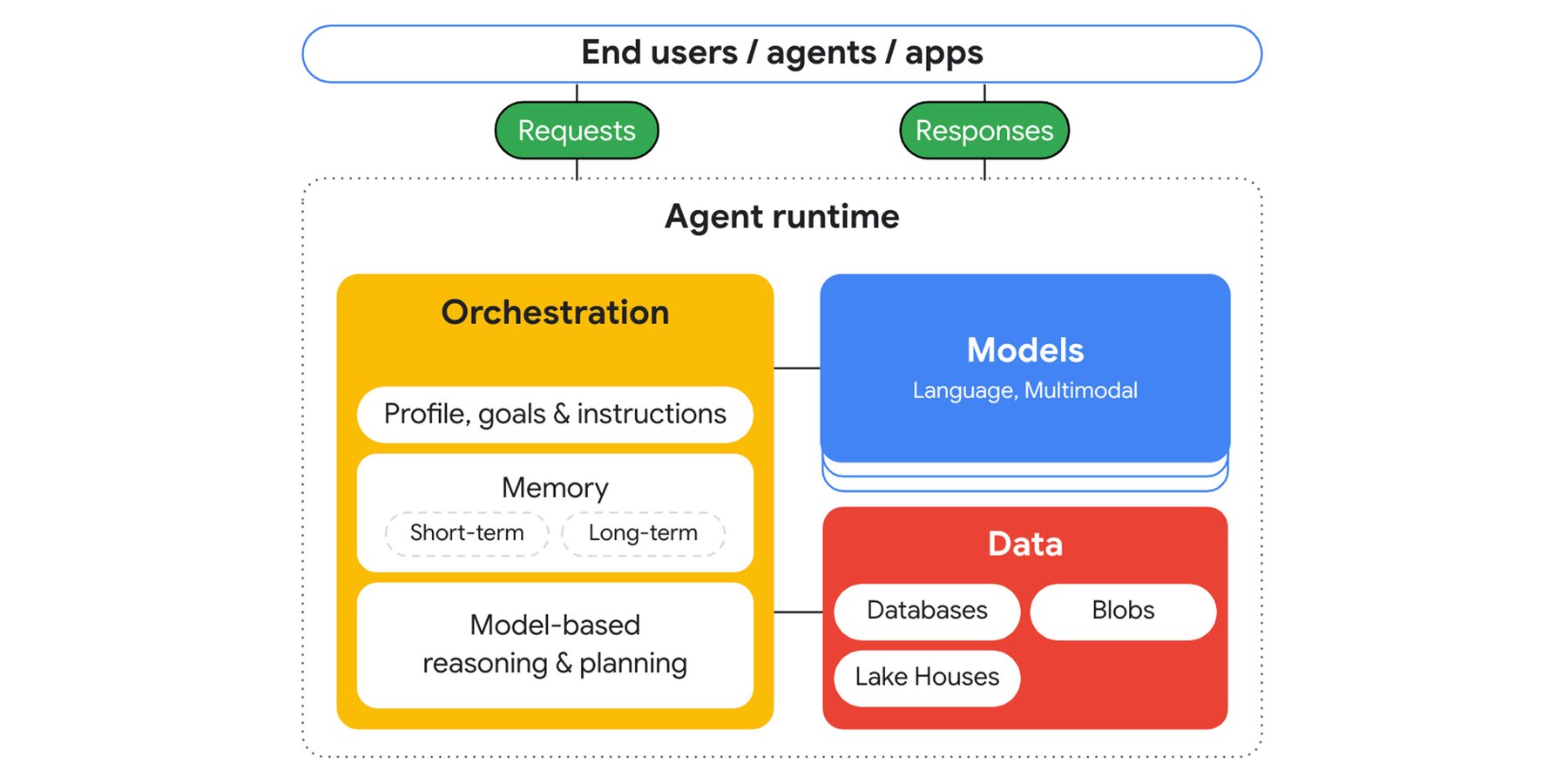
Agentic app architecture
The orchestration system within the agent runtime works with foundation models and tools to call service APIs, connect to databases, and even collaborate with other agents. There are a few core modules that construct an agent runtime.
- Orchestration: Maintains the memory and state of sessions, sends prompts to the model and parses the response. If the response includes tool calls then the orchestration performs the corresponding API call and includes the results in the next prompt.
- Models: Used to reason over goals to determine the next steps and generate a response.
- Data: Retrieves application data from other service APIs, operational data from databases, analytical data from lake houses, and unstructured data from blobs.
Developers can configure the agent with natural language instructions and examples to guide them. Then they can give access to various types of memory such as session histories, user profiles, and task profiles, and can augment it with task decomposition and planner services to break down complex requests into smaller work streams.
Connecting agents to Google Cloud Databases
Agents are only as powerful as the tools that they can use to perform their tasks. And most enterprise applications rarely use just a single data source. That is one reason why agentic orchestration has emerged as a new paradigm for LLM-powered applications to handle more complex tasks. Agents can select from a set of functions called “tools” which can access data or take actions which inform the next step. Using this dynamic, iterative process, agents can automate complex enterprise workflows.
However, there are several challenges developers face when creating and managing tools at scale. Agents often use multiple tools and frameworks as well as connect to various data sources which can be difficult to integrate. One of the most challenging tasks for agents is the discovery and connectivity to data sources. This process can be complex and introduce security challenges, while supporting multiple frameworks can be difficult to manage.
That’s where Gen AI Toolbox for Databases comes in, an open-source service that empowers application developers to connect production-grade, agent-based AI applications to databases. It streamlines the creation, deployment, and management of sophisticated gen AI tools capable of querying databases with secure access, robust observability, scalability, and comprehensive manageability. Gen AI Toolbox currently provides connectivity to popular open-source databases such as PostgreSQL, MySQL, Neo4j, Hypermode, as well as Google Cloud databases such as AlloyDB (+Omni), Spanner, and Cloud SQL.
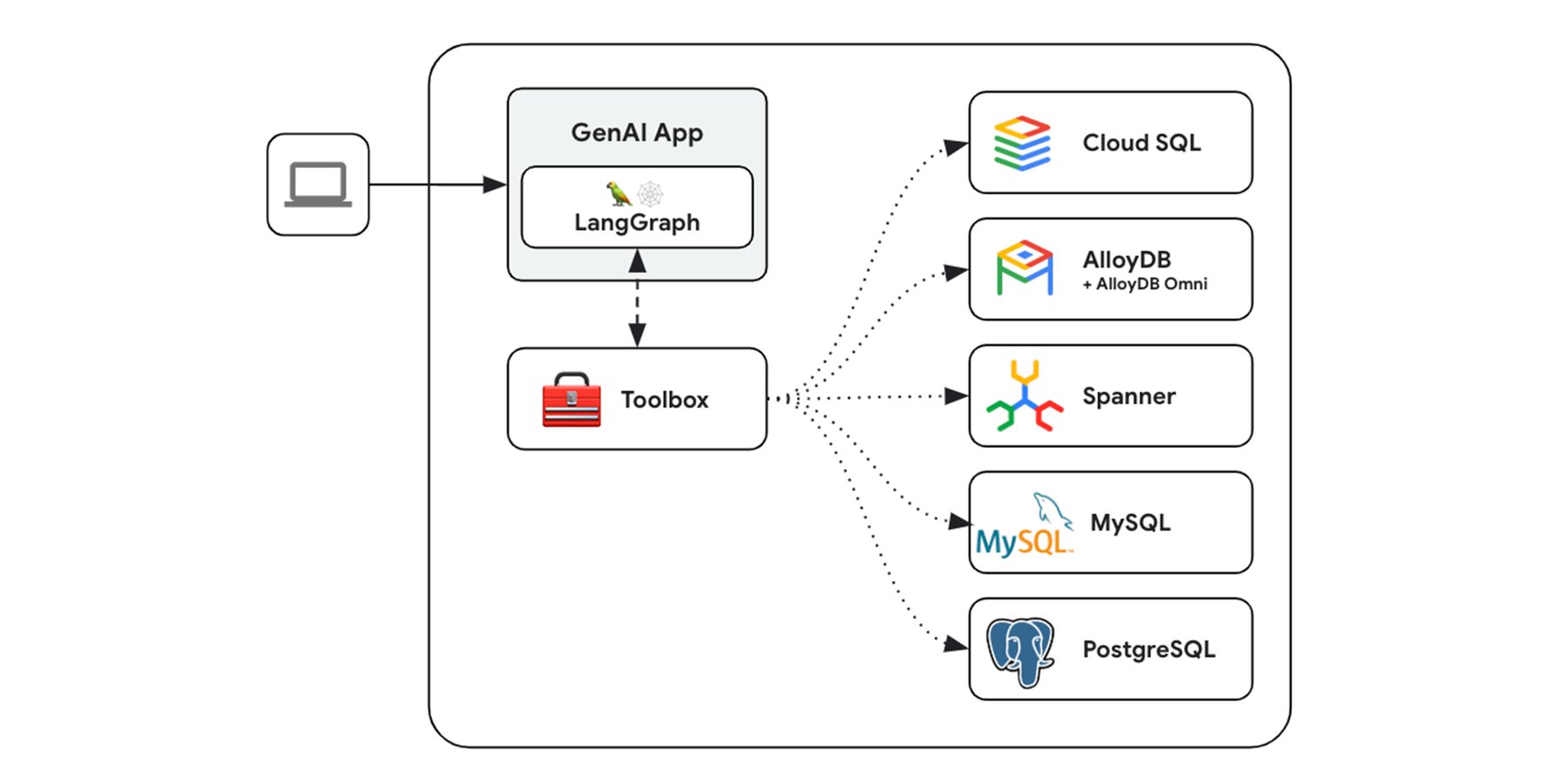
Gen AI Toolbox for Databases
Gen AI Toolbox for Databases improves how gen AI tools interact with data, addressing common challenges in gen AI tool management. By acting as an intermediary between the application's orchestration layer and data sources, it enables faster development and more secure data access, improving the production-quality of tools.
Using natural language to query databases with agents
Once your agents are connected to databases you can use a wide variety of methods to query the data. A recent technique that is gaining popularity is using natural language to query databases. Through the power of LLMs, your natural language questions such as:
“What are the cheapest direct flights from Boston to Denver in July?”
Can be converted to a SQL query like:
SELECT flight.id, flight.price, carrier.name, [...]
FROM [...]
WHERE [...]
ORDER BY flight.price ASC
AlloyDB provides the capability to convert natural language questions like these into SQL statements. This enables gen AI applications to more securely execute natural-language queries such as "Where is my package?" or "Who is the top earner in each department?" AlloyDB does this by translating the natural-language input into a SQL query specific to your database and filtering the results only to what the user of your application is allowed to view.
Since natural language is already used for LLM prompts, it would be efficient and easier for agents and gen AI apps to pass the queries to the database without having to convert them to SQL statements, if the database can understand natural language—opening up a new approach for data access and retrieval.
Handling complex data models for agents
For large organizations, it is common to have various data types and models. Furthermore, interconnected data is becoming increasingly important to customers for use cases such as knowledge graphs, recommendations, and fraud detection. This has been a challenging problem to solve for agents as it requires them to discover and traverse various data systems and combine the results afterwards.
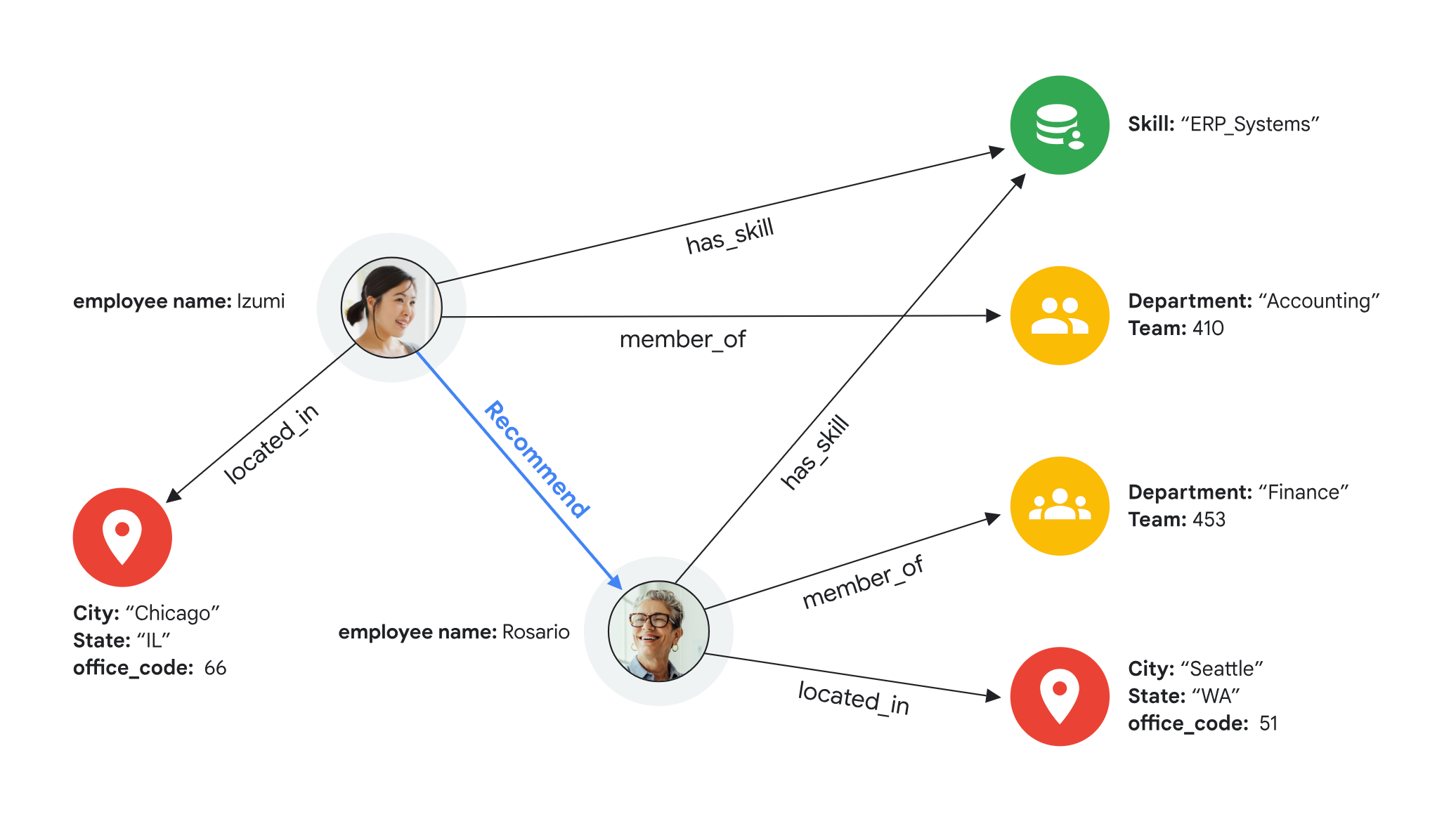
Graph-based models for connected data
With Graph built into Spanner this can be resolved with a simple call for an agent. Spanner is a multi-model database that supports differentiated graph, vector, and full-text search. Graph search will get the relevant results based on the pre-defined relationships, vector search can retrieve the categorical results for similarity searches, and full-text search can get the exact matches—together enabling hybrid search from a single database.
This provides a powerful way to provide enterprise context for agents across a wide variety of data models without having to combine the results separately.
Related News

Building the most open and innovative AI ecosystem
See Detail
Cloud Ace Wins 2024 Google Cloud Sales Partner of the Year - Southeast Asia Award for the Second Consecutive Time
See Detail
Making insights actionable with new Looker Studio scheduling capabilities
See Detail