Article
Introducing Seed Speech 2.0, a New Generation of Conversational Speech AI
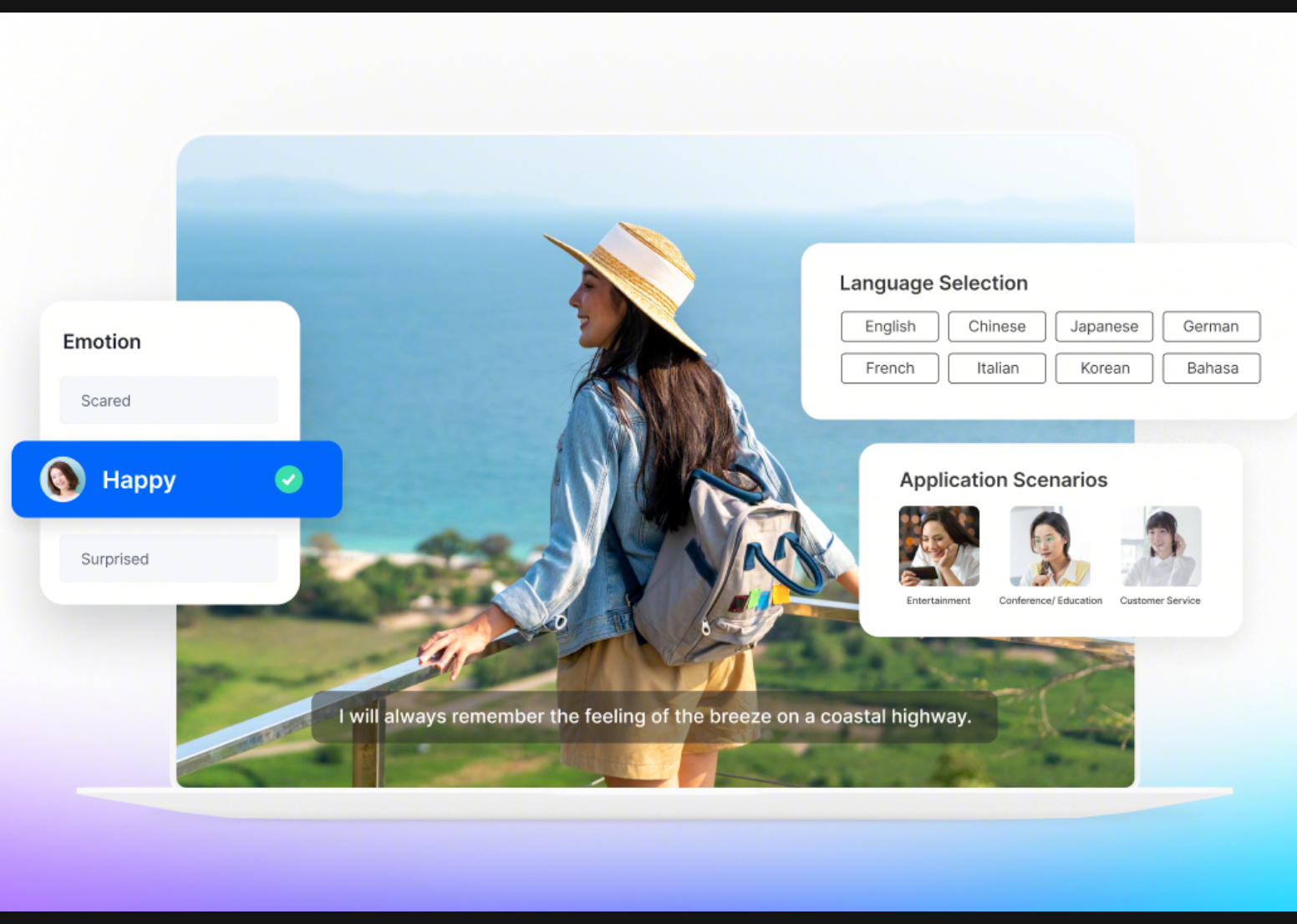
Expressive voice generation and accurate multilingual speech recognition in one system.
Voice has quietly become one of the most important interfaces in modern software. From AI assistants and customer support to video production and live transcription, speech systems increasingly shape how information is created, delivered, and understood.
But building reliable voice experiences has always required solving two different challenges: generating expressive speech, and accurately understanding what people say.
Today, BytePlus introduces Seed Speech 2.0, an advanced speech AI platform designed to address both.
Seed Speech 2.0 combines expressive text-to-speech (TTS 2.0) with accurate speech recognition (ASR 2.0) to enable natural voice interactions across applications such as content creation, AI assistants, call centers, dubbing, subtitling, and audio-video analysis.
At its core, Seed Speech 2.0 is built around a simple idea:
Voice technology should be capable of both expression and understanding.
Expressive speech generation with TTS 2.0
Seed Speech TTS 2.0 is designed to deliver expressive voice output with greater control and contextual awareness.
The model introduces a query–response speech synthesis mechanism, allowing it to interpret both conversational context and the generated response. This enables speech that reflects appropriate tone, rhythm, and pauses for the scenario.
Developers can shape how speech is delivered through text-based prompts and reference context, adjusting attributes such as emotion, tone, speech rate, pitch, timbre, and style. This flexibility allows voice output to be tailored for a wide range of applications including AI assistants, conversational agents, digital avatars, and media narration.
For structured or educational content, TTS 2.0 also supports accurate reading of formulas and symbols. Through targeted model training and optimization, the system achieves around 90% accuracy when reading complex formulas and symbols across subjects such as mathematics and science.
Accurate speech recognition with ASR 2.0
Seed Speech ASR 2.0 focuses on improving recognition accuracy across multilingual and real-world environments.
The system supports both streaming speech recognition and audio file transcription, enabling real-time voice interaction as well as large-scale audio analysis workflows.
ASR 2.0 introduces several key capabilities designed for modern voice applications.
It supports multilingual recognition across 51 languages, along with speaker emotion detection and real-time transcription.
Reinforcement learning improves contextual reasoning, allowing the system to interpret speech more accurately in dynamic conversations and improving contextual keyword recall by around 20%.
For device-based voice interaction, such as smart speakers, televisions, and wearable devices, the model improves far-field recognition performance and reduces recognition error rates by approximately 50%.
ASR 2.0 also introduces multimodal understanding, combining audio with image and video context to improve transcription accuracy in multimedia scenarios.
Enabling the next generation of voice applications
By bringing expressive speech generation and accurate recognition together, Seed Speech 2.0 enables a broad range of voice-driven experiences.
Organizations can use Seed Speech to power conversational AI assistants, automate customer support, generate narration for podcasts and audiobooks, produce video dubbing, and create real-time subtitles for events and conferences.
The platform also supports emerging applications such as digital avatars, chat companions, and voice interaction with AI-powered devices, while enabling audio and video understanding workflows across media and enterprise environments.
A new step forward for voice AI
As voice interfaces continue to expand across industries, developers and enterprises need systems that can both generate expressive speech and accurately understand spoken input.
Seed Speech 2.0 brings these capabilities together in a unified speech AI platform.
With expressive text-to-speech, multilingual speech recognition, contextual reasoning, and multimodal understanding, Seed Speech 2.0 helps organizations build the next generation of voice-enabled applications.
Related News

Announcing new capabilities for enabling defenders and securing AI innovation
See Detail
Chat with your data from anywhere: Announcing Google’s Conversational Analytics API
See Detail
Cloud Ace Wins 2024 Google Cloud Sales Partner of the Year - Southeast Asia Award for the Second Consecutive Time
See Detail