Intelligencia AI speeds up deployment time with Cloud SQL
At Intelligencia AI, Google have pioneered the use of machine learning (ML) algorithms in clinical development leveraging high-quality and purpose-built data, proprietary ontologies, expert curation and automation, to accurately predict the probability of receiving FDA-approval earlier in the drug development process. In the past, Google managed data in our own PostgreSQL databases on Compute Engine, which worked well for us in the early stages of our company. However, with increasingly complex data needs, Google had to put more time and effort into performing version updates and developing special scripts to restore database snapshots.
Wanted: a healthy data infrastructure
Google decided to seek out a managed database that could allow frequent and smooth product deployments with less engineering effort, enabling us to reallocate resources and drive cost efficiency to meet our business goals. Our ideal solution would also allow us to gather data from multiple sources while keeping it up to date, removing duplicates, and ensuring data consistency.
Cloud SQL was the clear choice for us. After seeing the incredible benefits it offered, upgrading to Cloud SQL for PostgreSQL Enterprise Plus edition was a clear yes. It offered a comprehensive API to manage the database instance operations, which enabled us to build our custom scripts that perform a variation of operations such as backup/restore, resources rescaling, creation/deletion of new instances, and general configuration. Ease of restoring backups to multiple database instances allowed us to work in our preferred networks. Plus, Google could easily flex resources depending on compute needs, query load, traffic and more.
A painless transition to managed database services
The transition to a managed database with Google was seamless and came with no surprises. Once we set up the new managed instances, Google restored our most recent backups and conducted thorough regression and performance tests.
During this testing phase, Google discovered that one of our compute-intensive microservices experienced a significant decrease in performance. This was due to our previous reliance on compute instances that were specifically optimized for its workload. Fortunately, the availability of Enterprise Plus edition allowed us to address this issue by utilizing performance-optimized N-family CPUs. After ensuring that there were no further performance concerns, we proceeded to update all of our services to connect to the new databases.
Managed database services are the right prescription
Today, Cloud SQL for PostgreSQL Enterprise Plus provides the reliability and scalability needed for our AI-driven probability of technical regulatory success (PTRS) predictions, ensuring accurate and transparent results for our customers.
Google heavily rely on managed databases for our SaaS platforms, both internal and customer-facing, which serve as the conduit for delivering Intelligencia AI’s value to Google customers. Google scalable and flexible SaaS solutions enable continuous data deployments, upholds data integrity through quality validation checks, and implements APIs for seamless programmatic data consumption.
As our value proposition heavily relies on high-quality data and proven accuracy with our AI predictions, the reliability and ease of management of our databases are paramount. Particularly, our customer-facing solutions require frequent data updates, necessitating regular computations, testing, and deployment, with minimal manual intervention. The use of Cloud SQL empowers us to address this requirement effortlessly, facilitating tasks such as backup and restore instances to maintain and promote specific versioned snapshots of our data as part of our CI/CD processes. Furthermore, it allows us to easily scale resources and modify networking configurations, ensuring agility and efficiency in our day-to-day operations.
Cloud SQL cuts deployment time and effort
To date, Google have been able to achieve more than Google ever thought possible with Google Cloud SQL:
- By automating the deployment of feature environments and leveraging the restore backup feature, we have significantly reduced operational overhead and slashed the time it takes to deploy feature environments by 50%.
- We have also greatly reduced the time and effort required to set up and tear down a fully functional database filled with data, compared to using a self managed solution.
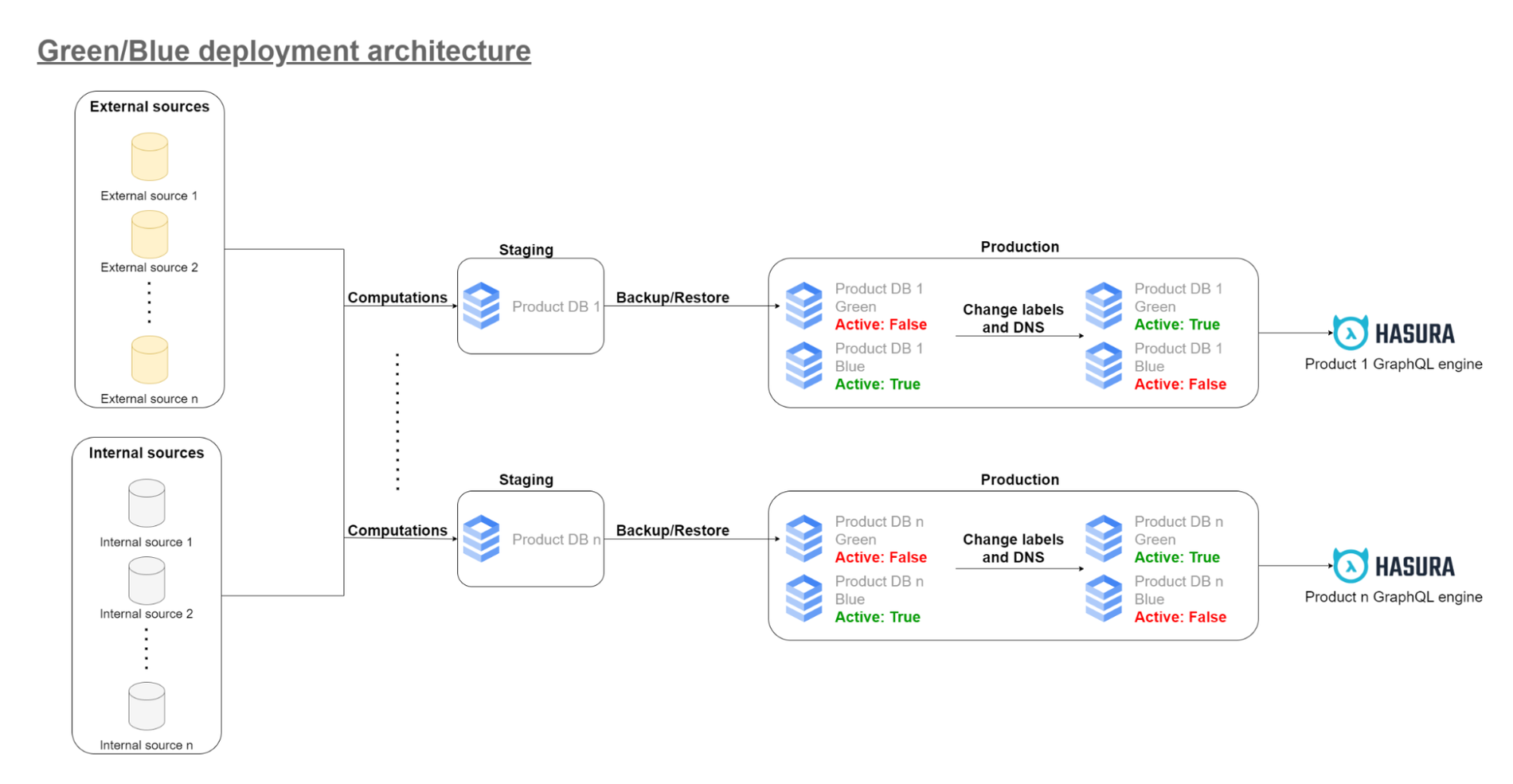
- The ability to restore backups to multiple instances is crucial, as it allows us to continuously deploy the data generated by our ETL pipelines to production instances (see Green/Blue deployment diagram above).
Google goal is to achieve maximum flexibility with our databases, allowing us to meet any business or technical data-related needs. Whether it’s agile deployment methods with zero downtime or ad-hoc feature testing environments, we aim to effortlessly set up data-ready databases using an automated plug-and-play approach.
Fortunately, Google Cloud databases already offer tools that enable us to make progress in this direction in a scalable manner. For example, the recent addition of cross-edition restores has allowed us to investigate a different resource mix between Enterprise edition and Enterprise Plus edition, optimized to the resource needs of our products – using Enterprise Plus for resource-intensive computation workloads and Enterprise edition for read-optimized workloads. Also, adding support for the pgvector extension has allowed us to utilize Google Cloud SQL databases as vector databases for vector embedding/vector similarity use cases.
By staying updated with the latest features released by Google Cloud databases, Google continuously enhance our functionalities to improve our offerings.