How Dataplex can improve data auditing, security, and access management
Data is one of the most important assets of any enterprise. It is essential for making informed decisions, improving efficiency, and providing a competitive edge. However, managing data comes with the responsibility of preventing data misuse. Especially in regulated industries, mishandling data can lead to significant financial and reputational damage. Negative outcomes such as data exfiltration, data access by unauthorized personnel, and inadvertent data deletion can arise if data is mis-managed.
There are multiple ways to help protect data in enterprises. These include encryption, controlling access, and data backup. Encryption is the process of encoding data into ciphertext. If done right, this makes it impossible for unauthorized users to decode the data without the correct key. Access control is the process of limiting access to data to authorized users only. Lastly, being able to audit your data management actions can help in proving that you are following the current regulations that affect your company while protecting one of your core competitive advantages.
It is important to choose the right security solutions for your enterprise. The potential cost of a data breach needs to be considered against the cost of protecting your data. Data security is an ongoing process. It is important to regularly review and update your security processes and tools.
In this blog post, Google discuss how you can discover, classify, and protect your most sensitive data using Cloud DLP, Dataplex, and the Dataplex Catalog and Attribute Store. This solution automates complex and costly data practices so you can focus on empowering your customers with data.
In most organizations, data is gathered regularly and this data can fall into one of two categories:
1. Sensitive data for which a specific policy needs to be attached to it according to the contents of the data (e.g. bank account numbers, personal email addresses). These data classifications are generally defined based upon:
a) Applicable regulatory or legal requirements
b) Critical security or resilience requirements
c) Business specific requirements (e.g., IP)
2. Non-sensitive data
In order to protect sensitive data and be able to follow the compliance requirements of your industry, at Google Cloud we recommend the usage of the following tools:
- Data Loss Prevention (Cloud DLP) helps developers and security teams discover, classify and inventory the data they have stored in a Google Cloud service. This allows you to gain insights about your data in order to better protect against threats like unauthorized exfiltration or access. Google Cloud DLP provides a unified data protection solution that applies consistent policies to data in a hybrid multi-cloud environment. It can also de-identify, redact or tokenize your data in order to make it shareable or usable across products and services.
- For BigQuery, Cloud DLP also provides a sensitive data discovery service that automatically scans all BigQuery tables and columns across the entire organization, individual folders, or select projects. It then creates data profiles for each table and column. These profiles include metrics like the predicted infoTypes, the assessed data risk and sensitivity levels, and metadata about the size and shape of your columns. Use these insights to make informed decisions about how you protect, share, and use your data.
- Dataplex is a fully managed data lake service that helps you manage and govern your data in Google Cloud. It is a scalable metadata management service that empowers you to quickly discover, manage, understand and govern all your data in Google Cloud.
Cloud DLP’s inspection jobs integrate natively with Dataplex. When you use a Cloud DLP action to scan your BigQuery tables for sensitive data, it can send results directly to Data Catalog in the form of a tag template.
Furthermore, to define how certain data should be treated Google are also providing the ability to associate data with attributes through Dataplex’s Attribute Store. This functionality represents a major shift in the approach to governing data as, previously, governance policies could only be defined at the domain level. Now, customers can support compliance with regulations, such as GDPR, by defining data classes, such as Personal Identifiable Information ‘PII data’, mapping the relevant PII attributes, and then defining the associated governance policies.
With Google Cloud, customers can govern distributed data at scale. Dataplex drastically increases the efficiency of policy propagation by mapping access control policies to tables and columns, and applying them to data in Cloud Storage and BigQuery.
Since Attribute Store, currently in Preview, supports tables published by Dataplex (in a Cloud Storage bucket, mounted as an asset in Dataplex). Soon, we expect Attribute Store will be able to attach attributes to any table.
A reference architecture is shown below, outlining the best practice for securing data using Attribute Store, in conjunction with Data Catalog tags which provide an explanation of the data.
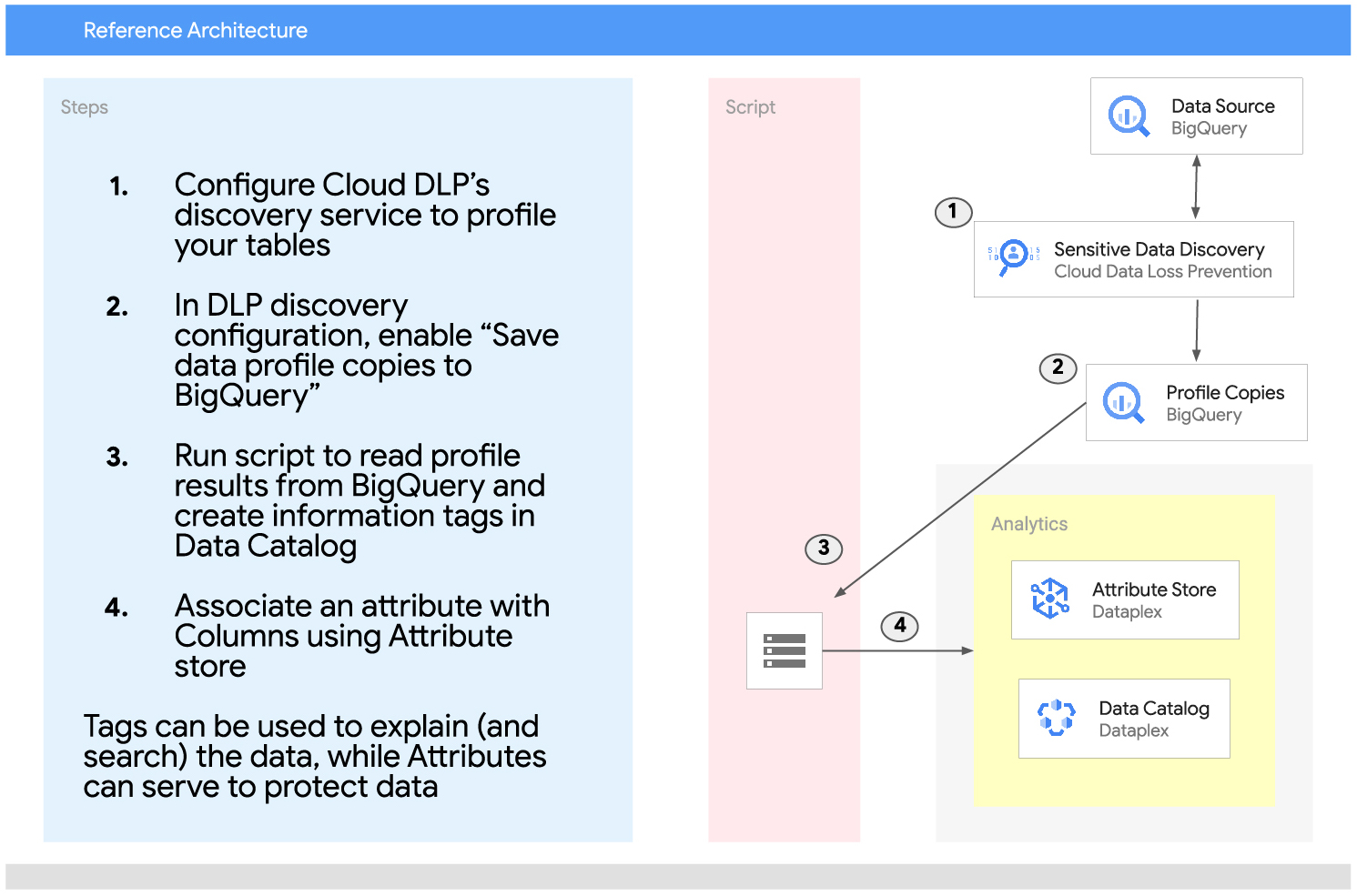
In the above diagram, Google see that Table columns are both informationally tagged (using Data Catalog) and associated with an attribute (using Attribute Store). Attribution tagging helps facilitate data protection at scale while the Data Catalog uses tags to describe the data and enhance searchability.
It is important to note that Data Catalog tags are indexed. Therefore, Google begin the process by creating this matching DLP infoType for the relevant Data Catalog Tag and Attribute. Then, when DLP matches the infoType, a Data Catalog Tag is created and an Attribute is associated with the data.
Implementing this approach to discovering, classifying, and protecting your organization’s data can help to ensure that you handle this incredibly valuable asset accordingly.